
The transition from academic or self-taught artificial intelligence study to entry-level employment has grown increasingly hostile in the 2024–2026 labor market. Recent college graduates, typically possessing zero to two years of professional experience and foundational familiarity with tools like ChatGPT, are encountering a systemic bottleneck. Despite completing rigorous online coursework from leading platforms, these candidates frequently face hundreds of unanswered applications and automated rejections. Digital communities, particularly job-focused Discord servers and subreddits such as r/learnmachinelearning and r/cscareerquestions, are replete with testimonials of job-search exhaustion, burnout, and a profound disconnect between what online courses teach and what enterprise hiring managers actually demand.
The core of this systemic failure lies in an educational paradigm that heavily prioritizes theoretical knowledge and isolated modeling exercises over end-to-end production deployment, strategic networking, and commercial awareness. Candidates are graduating from massive open online courses with portfolios filled with static Jupyter Notebooks, lacking the deployable templates, application programming interface integrations, and quantifiable performance rubrics required to survive modern applicant tracking systems. Furthermore, an influx of AI-generated resumes has saturated recruitment pipelines, forcing hiring managers to rely on demonstrable proof of skill—live applications, verifiable metrics, and direct outreach—rather than mere course completion certificates.
This comprehensive analysis evaluates the specific curricula of prominent AI upskilling courses, quantifies the reality of learner outcomes based on 2023–2025 market data, identifies the critical educational gaps preventing entry-level hiring, and provides a highly detailed, 60-day architectural and strategic protocol to transform a standard curriculum project into a competitive, interview-generating asset.
Curricular Audit of Dominant AI Upskilling Platforms
To understand the foundational skills entry-level candidates possess, it is necessary to audit the specific curricula, pricing models, and hybrid skill integrations of the market's most popular learning platforms: Udemy, fast.ai, and freeCodeCamp. These platforms dominate the self-taught landscape and dictate the baseline technical vocabulary of the modern entry-level applicant pool.
Udemy: "ChatGPT for Developers: Mastering OpenAI's APIs with Python"
The Udemy platform serves as a massive aggregator of tactical, task-oriented micro-courses and extensive bootcamps. Among the most relevant for modern entry-level job seekers is "ChatGPT for Developers: Mastering OpenAI's APIs with Python" and parallel generative AI curricula. This ecosystem is highly modular and specifically engineered for the rapid integration of large language models into existing software ecosystems.
The primary value proposition of this course profile is its focus on hybrid skills. It does not strictly teach machine learning mathematics; rather, it teaches software developers how to orchestrate artificial intelligence. Candidates learn to bridge the user-to-developer gap by integrating ChatGPT into HTML, React, Python, R, and SQL applications. The coursework emphasizes developer productivity, code generation, and debugging, transforming the candidate into an AI-augmented software engineer.
Udemy's pricing model is highly variable due to aggressive, algorithmic discounting. While the initial listed price for such comprehensive bootcamps often displays as $109.99, frequent sales typically reduce the barrier to entry to approximately $19.99 or lower, making it highly accessible to recent graduates.
| Module Focus Area | Core Technologies Taught | Primary Learning Objective |
|---|---|---|
| API Foundations | OpenAI Python SDK, HTTP Requests | Managing API keys securely, setting up billing, and making initial programmatic calls to language models. |
| Prompt Engineering | System Prompts, Few-Shot Learning | Structuring deterministic outputs from probabilistic models, mastering temperature and top-p settings. |
| Framework Orchestration | LangChain, GPT4ALL, Hugging Face | Constructing data-aware and agentic applications that connect language models to external data sources. |
| Application Integration | React, SQL, HTML/JS | Embedding generative capabilities into traditional web frameworks and database querying systems. |
fast.ai: "Practical Deep Learning for Coders"
Fast.ai, co-created by Jeremy Howard and Rachel Thomas, is universally recognized in developer communities for its unique pedagogical philosophy. It rejects the traditional, math-heavy, bottom-up approach of university degrees in favor of a top-down methodology, allowing students to build state-of-the-art models in the first lesson before dissecting the underlying calculus and linear algebra.
The 2024–2025 iteration of the curriculum is divided into two distinct parts. Part 1 focuses on practical applications using PyTorch and the fastai library. Part 2, titled "Deep Learning Foundations to Stable Diffusion," is designed for advanced practitioners and explores the mathematics of diffusion models, autoencoders, and multi-layer perceptrons from scratch. Fast.ai focuses heavily on deep learning applications across computer vision, natural language processing, tabular analysis, and collaborative filtering recommendation systems. The course integrates modern ecosystems, including Hugging Face Transformers, Datasets, and Gradio for simple web deployments.
The entire course—including the video lectures, interactive Jupyter notebooks hosted on Kaggle or Paperspace, and the accompanying textbook—is entirely free, positioning it as the premier foundational resource for budget-conscious graduates.
| Curriculum Section | Module Count | Core Topics and Projects |
|---|---|---|
| Part 1: Practical Deep Learning | 9 Lessons (~13.5 hours) | Computer vision (e.g., bird vs. forest image classifiers), tabular data, collaborative filtering, neural net foundations, random forests, deployment. |
| Part 2: Deep Learning Foundations | 19 Lessons (~30 hours) | Stable Diffusion, matrix multiplication, mean shift clustering, backpropagation, attention mechanisms, transformers, latent diffusion. |
freeCodeCamp: "Machine Learning with Python"
As a donor-supported nonprofit, freeCodeCamp provides a globally accessible, linear curriculum. The "Machine Learning with Python" certification is a highly utilized pathway for entry-level candidates attempting to signal formal AI competency. The certification is designed to take approximately 300 hours to complete and represents a significant time investment for self-taught developers.
The coursework is divided into distinct sections covering machine learning fundamentals, core learning algorithms (regression, clustering, classification), neural networks with TensorFlow, convolutional neural networks, natural language processing with recurrent neural networks, and reinforcement learning via Q-learning. To claim the certification, learners must pass automated tests on five mandatory portfolio projects. The platform and all associated certifications are completely free forever.
| Certification Project | Algorithm / Architecture | Practical Application |
|---|---|---|
| Rock Paper Scissors | nth-order Markov Chain | Developing a program with a >60% win rate against varied opponent strategies using historical match data. |
| Cat and Dog Image Classifier | Convolutional Neural Network (CNN) | Building a binary image classification model utilizing TensorFlow and Keras. |
| Book Recommendation Engine | K-Nearest Neighbors (KNN) | Implementing unsupervised learning to cluster and recommend literature based on user similarity. |
| Health Costs Calculator | Linear Regression | Utilizing tabular data to predict continuous numerical outputs related to medical expenses. |
| SMS Text Classifier | Recurrent Neural Network (RNN/LSTM) | Classifying raw text messages as either legitimate ("ham") or malicious ("spam") advertisements. |
Comparative Analysis of Dominant AI Upskilling Platforms (2024-2025)
| Comparative Metric | Udemy | fast.ai | freeCodeCamp |
|---|---|---|---|
| Pricing | $19.99 - $109.99 | Free | Completely Free |
| Time Commitment | Variable | ~45+ hours core | 300 hours |
| Core Focus | LLM IntegrationPrompt Engineering | Applied Deep LearningModel Training | Machine Learning FundamentalsNeural Networks |
| Primary Tech Stack | OpenAI APIPython, HTML, R, SQL | PyTorch, fastaiHugging Face | TensorFlowPython |
| Portfolio Output Format | API ScriptsApp Creation | Jupyter NotebooksGradio Demos | 5 Required ProjectsStandardized Python Scripts |
While fast.ai and freeCodeCamp provide rigorous, free foundational training in model architecture, Udemy's paid ecosystem focuses heavily on the orchestration and integration of commercial APIs.
Empirical Learner Outcomes and the Market Reality (2023–2025)
Despite the proliferation and high quality of the educational material outlined above, the empirical outcomes for entry-level candidates relying solely on these certifications are overwhelmingly negative. The translation from course completion to hired employee is fraught with systemic market barriers, fundamentally altering how candidates must approach their job search.
The Certificate-to-Job Illusion
A prevailing, yet ultimately false, narrative in entry-level tech forums is that acquiring a certificate from a reputable platform like freeCodeCamp or completing the fast.ai curriculum guarantees employment. An analysis of forum data and learner reviews from 2023 to 2025 across platforms like Reddit reveals a starkly different reality. Industry veterans and hiring managers consistently state that free certificates possess negligible standalone value on a professional resume.
The primary utility of a certification is the structured learning it provides, not the credential itself. A highly upvoted commentary from a senior developer on the r/FreeCodeCamp subreddit explicitly noted that the certificate itself has very little value on a resume, emphasizing that hiring managers prioritize portfolio pages, GitHub repositories, and practical projects or real-world experience over educational achievements. The completion-to-job rate for candidates possessing only a certificate and basic, unadulterated course projects is effectively zero without aggressive supplementary networking or prior related software engineering experience.
The Collapse of the Entry-Level Application Pipeline
The macroeconomic environment of 2024 and 2025 has exacerbated these difficulties. Following aggressive over-hiring during the early 2020s, technology firms have tightened budgets, leading to an oversaturated market of experienced talent competing for lower-level roles. This contraction has forced entry-level candidates into a highly defensive posture, applying to hundreds of roles with minimal success.
Furthermore, the very technology these candidates are studying—generative AI—has weaponized the application process. Job seekers are utilizing AI to mass-generate resumes and cover letters, resulting in an avalanche of applications for every open position. Hiring pipelines are inundated with hundreds of AI-generated, keyword-stuffed resumes that often blur the line between genuine capability and algorithmic hallucination. Consequently, recruiters have deployed advanced AI screening tools to parse this volume. These automated systems frequently filter out non-traditional candidates or those lacking specific elite university credentials, creating a paradox where self-taught candidates are filtered out by algorithms before a human ever views their portfolio.
Candidates repeatedly report applying to thousands of positions over a 6-to-12-month period with near-zero callback rates, leading to severe burnout and disillusionment. The timeline for a successful career pivot into AI engineering for self-taught developers is currently documented at an average of 12 to 18 months of sustained, intense project building, vastly exceeding the duration of the courses themselves.
Portfolio Deployment Success
The data clearly demarcates the line between successful and unsuccessful candidates: successful candidates do not submit course projects; they submit products. Candidates who transition from tutorial followers to product builders experience a dramatically higher success rate.
The referral wall is a significant barrier; documented success stories from 2024–2025 routinely involve either a direct referral or an unconventional path, such as emailing paper authors or engaging directly with hiring managers on technical forums. Cold applications rarely work at top companies. Portfolio mistakes that lead to rejection include projects ending at Jupyter notebooks without deployment, submitting tutorial-level work like MNIST classifiers or Titanic predictions, and failing to provide deployment links or architecture diagrams. Successful portfolios demonstrate end-to-end implementation, highlighting data ingestion, model serving, and user interface design.
Five Critical Educational Gaps in Current AI Portfolios
If the coursework is technically sound but the outcomes are poor, the failure lies in the translational layer between academia and industry. An analysis of feedback from hiring managers and frustrated applicants on forums such as r/learnmachinelearning reveals five systemic gaps in current AI portfolio-building curricula.
Gap 1: The Jupyter Notebook Dead End and Weak Integrations
The most fatal error made by entry-level candidates is presenting a portfolio consisting entirely of Jupyter Notebooks. Courses like fast.ai and traditional university curricula rely heavily on Jupyter Notebooks or Google Colab because they are excellent environments for exploratory data analysis, plotting loss curves, and experimenting with hyperparameters.
However, in an enterprise setting, a model sitting in a notebook is fundamentally useless. Industry requires AI models to be deployed, scaled, and integrated into existing business logic. When recruiters or hiring managers review a candidate's GitHub repository, they spend an average of less than thirty seconds assessing the code. If they encounter a .ipynb file that requires them to manually download data, navigate complex dependency installations, and execute code cells sequentially, they will simply close the tab and move to the next candidate.
Existing courses thoroughly teach model architecture but frequently skip the final, critical step of production deployment. Candidates fail to bridge the user-to-developer gap because they do not learn how to containerize their models using Docker, build robust web application programming interfaces using FastAPI or Flask, or deploy their inference engines to cloud infrastructure platforms like Amazon Web Services, Google Cloud Platform, or Render. The market data is unequivocal: a candidate with a mediocre model served via a robust, highly available API will consistently outcompete a candidate with a mathematically perfect model trapped in a local notebook environment.
Gap 2: The Absence of the Metric Rubric
When candidates do build projects, they often struggle to articulate the business value of their creation. They describe the mechanics of how they built the model rather than why the model matters in a commercial context. In professional environments, AI engineering projects are evaluated against strict, multidimensional performance criteria. Academic courses heavily index on model accuracy, but enterprise hiring managers evaluate candidates on a broader spectrum of operational viability.
According to advanced institutional frameworks, such as the graduate rubrics utilized at Northeastern University and established industry standards, a portfolio-worthy AI project must be evaluated across five explicit metrics: Quality, Latency, Cost, Safety, and Adoption.
| Evaluation Metric | Enterprise Definition | Academic Portfolio Gap |
|---|---|---|
| Quality | Evaluates core performance beyond simple accuracy. Focuses on precision, recall, F1-scores, and behavior under domain shifts or edge cases. | Students report flat accuracy percentages on clean, static datasets (e.g., 98% on MNIST) without testing real-world, noisy data distributions. |
| Latency | Measures the speed and responsiveness of the application. Crucial for user-facing features like copilots or real-time search, requiring strict millisecond targets. | Models are run locally without profiling inference time. Candidates lack experience optimizing batching or throughput for web deployments. |
| Cost | Focuses on the financial efficiency of the system, calculating the cost per inference run (e.g., API token usage or cloud compute resources) at scale. | Students utilize free academic tiers or local GPUs, failing to demonstrate an understanding of how model size impacts enterprise operational budgets. |
| Safety | Identifies potential risks and implements simple guardrails to mitigate prompt injections, personal data leaks, or hallucinatory content generation. | Models are built assuming benevolent users. Portfolios rarely include red-teaming reports, content moderation layers, or input validation logic. |
| Adoption | Measures real-world utility by tracking if real users have interacted with the application, documenting feedback, and iterating on the design. | Projects remain theoretical exercises unseen by actual end-users, missing the crucial product management loop of user-driven iteration. |
Without addressing this rubric, a portfolio project appears academic rather than enterprise-ready. Candidates must shift their vocabulary from purely algorithmic discussions to include these operational metrics.
The Enterprise AI Evaluation Framework
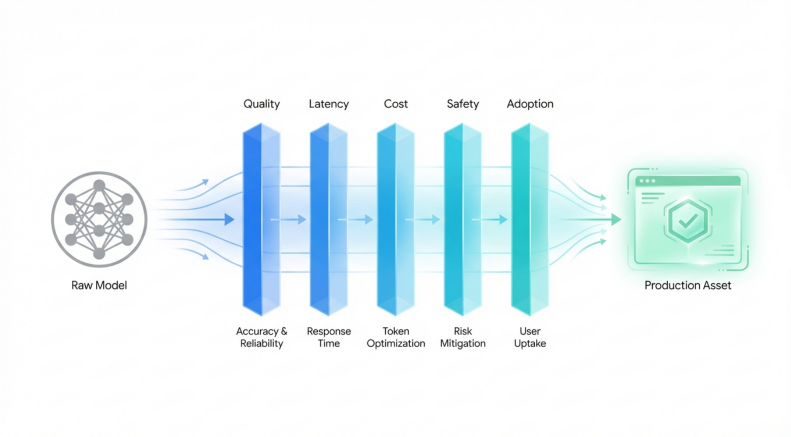
Academy ourses heabily index on model Quality, but enterprise hiring managers evaluate candidates on their ability to balance accuracny against Latency, cost, safet and end-user adoption,
Gap 3: Missing Go-to-Market Recruiter Scripts and the Hidden Job Market
Technical upskilling courses operate under the assumption of a strict meritocracy: build a mathematically sound model, and employers will actively seek you out. In the 2026 job market, this is a demonstrably false assumption. Courses fail entirely to teach the go-to-market strategy of job hunting.
Candidates are mass-applying to online portals, functioning essentially as automated spam, and achieving zero visibility against applicant tracking systems configured to reject non-traditional backgrounds. Successful market entry requires circumventing the ATS entirely by navigating the hidden job market through targeted networking on platforms like LinkedIn, Discord, and Reddit. On Discord, tech and creative servers host niche discussions where founders and hiring managers casually share "not-yet-posted" openings. Meanwhile, Reddit acts as a massive open forum featuring job leads that never appear on traditional job boards.
Courses fail to provide deployable outreach templates or recruiter scripts. A junior engineer must know how to message a hiring manager respectfully without demanding an interview, bypassing the noise of the application portal. The required skill involves writing a highly targeted, three-sentence pitch: stating a unique value proposition, highlighting one specific metric from their portfolio, and linking to a 60-second video demonstration or a clean GitHub repository. The failure to bridge this communication gap leaves highly skilled coders utterly invisible to the market, unable to articulate their value to non-technical talent acquisition teams.
Gap 4: Disconnect from Production-Ready Agentic Systems
While traditional machine learning—such as random forests and basic convolutional neural networks—remains valuable in specific domains, the explosive enterprise demand is currently centered on Agentic AI and advanced large language model pipelines. However, there is a severe educational gap regarding how to build and evaluate autonomous AI agents safely.
Candidates who experiment with generative AI often build simple wrapper applications around the OpenAI API. When these applications fail in production, it is rarely due to the underlying model's intelligence; it is due to a failure in architectural orchestration. Modern agentic systems require evaluation across multiple interconnected layers. The reasoning layer must formulate a logical plan, the action layer must select the correct external tools and API parameters, and the execution layer must complete the autonomous loop efficiently without exhausting token limits or entering infinite loops.
Furthermore, courses rarely teach the implementation of safety layers, such as real-time content filters, rate limiting, intent validation, and output moderation, which are mandatory for enterprise compliance and brand protection. Candidates build powerful tools without the necessary braking systems, rendering their projects unviable for corporate integration.
Gap 5: Tutorial Hell and the Lack of Architectural Thinking
Finally, the highly structured nature of many free online certifications inadvertently traps students in a cycle commonly referred to as "Tutorial Hell." Curricula like freeCodeCamp provide highly scaffolded environments where students pass automated tests by writing specific, isolated lines of code to achieve a predetermined outcome. While this methodology is excellent for initial syntax memorization and basic concept introduction, it robs the student of the opportunity to develop true architectural thinking.
When a student is handed a clean, pre-processed, perfectly formatted dataset in a CSV file and told to implement a predefined algorithm, they bypass the most difficult and time-consuming aspects of real-world AI engineering: ambiguous problem definition, messy data collection, rigorous cleaning, infrastructure design, and deployment strategy. Hiring managers prioritize candidates who demonstrate end-to-end implementation and real-world problem-solving over those who merely execute tutorial-level predictions on highly sanitized datasets. The market demands engineers who can construct the entire factory, not just operate a single machine within it.
The 60-Day Transformation Protocol: Doubling Interview Callbacks
To break out of the rejection cycle, a candidate must stop acting like a student submitting homework and start acting like a production engineer shipping software. This requires taking one existing, baseline tutorial project and transforming it into a shippable, enterprise-grade asset.
For this strategic protocol, we will utilize the "Neural Network SMS Text Classifier," which serves as the final required project in the freeCodeCamp Machine Learning with Python certification. In its default, academic state, this project is a local Python script utilizing TensorFlow to classify text as either "spam" or "ham" based on a static, pre-provided dataset. Submitted as-is, linked solely as a script in a GitHub repository, it will generate zero interview callbacks.
By applying the following 60-day, four-phase practical transformation, a recent graduate can elevate this academic script into a high-signal portfolio piece designed to bypass ATS algorithms and directly impress technical hiring managers.
Phase 1: Architectural Robustness and MLOps Integration (Days 1–15)
The primary objective of the first two weeks is to break the model out of the localized Jupyter Notebook environment and wrap it in standard production architecture. The model must transition from a script to a service.
The first step requires refactoring and modularization. The candidate must abandon the .ipynb notebook format entirely. The codebase should be rewritten utilizing Object-Oriented Programming principles across standard Python .py files. The architecture must separate the data ingestion and preprocessing logic, the core model training loop, and the active inference execution into distinct, maintainable modules.
Following refactoring, the model must be made accessible over the web via an Application Programming Interface. The candidate should utilize FastAPI, a modern, high-performance web framework for building APIs with Python. The API must be configured to accept a JSON payload containing the raw SMS text, process it through the loaded model weights, and return a structured JSON response detailing the classification (spam/ham) alongside a probabilistic confidence score.
Finally, to eliminate the ubiquitous "it works on my machine" problem—frequently caused by dependency conflicts with libraries like TensorFlow—the project must be containerized. The candidate will write a declarative Dockerfile that cleanly packages the Linux environment, the FastAPI application, the pre-trained model weights, and the exact pip dependencies into a single, universally deployable container image.
Phase 2: Implementing the 5-Metric Rubric (Days 16–30)
With the baseline architecture constructed, the candidate must actively measure, tune, and document the system against the enterprise metrics demanded by modern hiring rubrics.
| Metric Focus | Actionable Implementation Task |
|---|---|
| Quality | Implement a comprehensive automated testing suite utilizing pytest. Move beyond binary accuracy by generating a confusion matrix to display the specific precision and recall rates for both the "spam" and "ham" classifications, proving an understanding of false positives in a business context. |
| Latency | Profile the FastAPI endpoint under load. Utilize tools to measure the exact response time of the inference cycle. Set a strict target (e.g., sub-200 milliseconds per inference) and document the specific preprocessing optimizations required to achieve that threshold. |
| Cost | Calculate the projected computational overhead. If the container is deployed on cloud compute instances, estimate the financial cost per 1,000 API calls based on CPU and memory utilization, demonstrating commercial awareness to potential employers. |
| Safety | Implement strict input validation logic. Design the system to handle unexpected inputs—such as empty strings, excessively long texts, or SQL injection attempts—gracefully. Utilize the Pydantic library to validate input schemas and lengths before the data ever reaches the neural network. |
| Adoption | Deploy the finalized Docker container to a accessible cloud provider, such as Render, AWS EC2, or Hugging Face Spaces. Construct a clean, intuitive front-end user interface using Streamlit, allowing non-technical users to type a message and view the classification instantly. |
Phase 3: The Shippable Deliverable and Documentation (Days 31–45)
A flawlessly deployed application remains invisible without world-class documentation. The GitHub repository must transition from reading like a university homework submission to functioning as a technical marketing landing page.
The repository's README file is the highest-leverage asset in the candidate's portfolio. It must be structured with a professional executive summary, a visual architecture diagram outlining the data flow from the Streamlit frontend to the FastAPI backend, and an explicit, quantified breakdown of the 5-Metric Rubric outcomes. The candidate must assume the reviewing recruiter will only look at the page for thirty seconds; therefore, the link to the live deployment and an animated GIF demonstrating the working application must be positioned at the very top of the document.
Furthermore, the candidate must record a concise, 60-to-90-second video walkthrough utilizing screen recording software such as Loom. This video should not focus on scrolling through lines of code. Instead, it must show the live web application in action, demonstrate a malicious spam text being successfully blocked, and briefly state the latency and precision metrics achieved. This specific deliverable proves communication clarity and commercial awareness—soft skills that are highly sought-after yet rarely demonstrated in entry-level applications.
Phase 4: Targeted Outreach Execution (Days 46–60)
With a verifiably production-ready asset complete, the candidate must immediately cease submitting blind applications through traditional job portals. The final fifteen days of the protocol are dedicated entirely to strategic networking and direct, cold outreach to hiring managers and technical recruiters via LinkedIn and Discord.
Candidates should leverage generative AI tools to analyze target job descriptions, identify the appropriate hiring manager or senior engineer on the team, and draft highly personalized, low-pressure outreach messages. The psychological goal of this outreach is not to beg for an immediate interview, but to initiate a peer-to-peer technical conversation based on mutual professional interests.
A highly effective outreach script bypasses generic pleasantries and follows a precise structural formula: it opens with a hook referencing a mutual technical interest or the company's recent engineering challenges, delivers a one-line value proposition demonstrating direct relevance, highlights a specific performance metric from the newly built portfolio project, and closes with a soft, non-demanding call to action.
For example, a candidate might utilize the following framework for LinkedIn outreach: "Hi [Name], I saw your team's recent post regarding the scaling of backend infrastructure and noticed you are hiring for a Junior AI Engineer. I recently architected and deployed a containerized NLP text classifier using FastAPI that processes inference in under 200 milliseconds with 94% precision. I have documented the architecture and load-testing metrics here: [Link to 60-second Loom/GitHub]. Would you be open to a brief chat about the technical challenges your team is tackling this quarter?"
This strategic approach completely circumvents the automated tracking systems that plague the modern job search. It provides immediate, verifiable proof of technical competence, demonstrates an acute understanding of vital production metrics such as latency and precision, and decisively positions the candidate as an active, capable problem-solver rather than a passive, unproven student.
Conclusion
The widening chasm between entry-level artificial intelligence job seekers and successful employment is rarely caused by a fundamental lack of mathematical knowledge or coding syntax. Courses like fast.ai and freeCodeCamp provide exceptional, freely accessible foundational training in model architecture and Python programming. The systemic failure lies in the final mile of the educational journey: the transition into production engineering, system deployment, and commercial communication.
By recognizing that enterprise hiring managers evaluate candidates on system architecture, deployment reliability, and the comprehensive 5-Metric Rubric of Quality, Latency, Cost, Safety, and Adoption—rather than isolated academic notebook accuracy—candidates can fundamentally pivot their job search strategy. By intentionally investing sixty days to transform a single, standard tutorial project into a fully deployed, containerized application with a live API, and coupling that tangible asset with targeted, metric-driven LinkedIn outreach, recent graduates can effectively bypass automated screening algorithms. This methodology shifts the candidate's profile from an unproven student to a shippable engineer, dramatically increasing their market visibility and interview conversion rates in a highly saturated and competitive technological landscape.