
The landscape facing the college graduating class of 2026 is characterized by distinct macroeconomic headwinds, evolving corporate vocabularies, and unprecedented technological shifts. Graduates are entering a cooling labor market where employers project a mere 1.6% increase in entry-level hiring compared to the previous year. Early indicators reveal a contracting private sector, with late 2025 reports showing consecutive months of net job losses reminiscent of the 2020 pandemic recession, alongside significant downward revisions of previous employment gains. Consequently, unemployment rates for recent graduates have climbed steadily across various global regions, shifting the power dynamic firmly back to cautious employers.
Compounding this challenging macroeconomic job market are intense administrative and psychological hurdles that uniquely affect the current cohort of entry-level talent. Financially, graduates are burdened by complex student debt structures and a high cost of living. Psychologically, this debt causes severe distress, with millions of borrowers reporting hopelessness and actively delaying major life milestones such as homeownership or family planning. Furthermore, the modern workplace has developed a highly toxic vernacular that obscures intent and demands extensive emotional labor to navigate. Graduates must decipher a culture defined by "resenteeism," "coffee badging," and performative initiatives.
To survive, adapt, and thrive in this environment, non-coding graduates must master the operational use of Large Language Models (LLMs). This report establishes a comprehensive pedagogical framework consisting of 15 gamified "Prompt Quests." These exercises operate on the principle of stealth learning: they explicitly solve immediate early-career pain points—such as decoding jargon or negotiating starting salaries—while implicitly training the user in advanced prompt engineering mechanics, moving them from passive artificial intelligence consumers to active operators.
The 2026 Graduate Landscape: Macroeconomic Headwinds and Regional Shifts
The broader economic environment for the Class of 2026 is one of caution and stabilization following years of post-pandemic volatility. Employers have given the current job market a mere "fair" rating, a designation last seen in 2021 when overall hiring projections were entirely flat. The recruitment cycle itself has been altered by this uncertainty, with recruiters shifting a significantly larger percentage of their hiring activities to the spring (37% for full-time hires) rather than relying on the traditional autumn recruiting periods. This delay tactics suggest that organizations are taking a highly measured approach to expansion, waiting for fiscal clarity before committing to entry-level headcount.
The United States private sector has demonstrated notable fragility, unexpectedly shedding 32,000 jobs in key sectors while economists had initially forecast a 50,000-job gain. This volatility whipsaws candidate confidence, as graduates send hundreds of applications into digital systems only to be met with automated silence. Similarly, the United Kingdom reflects an anemic economic posture. Graduate Outcomes data points to higher early unemployment for recent cohorts, lower levels of professional-level employment attainment, and a consequential increase in students deferring their entry into the workforce by enrolling in postgraduate study programs.
However, beneath the national averages lie distinct regional opportunities that savvy graduates can exploit. While major metropolitan centers like London and Silicon Valley remain highly competitive and prohibitively expensive, regional hubs are experiencing localized booms driven by infrastructure investments and digital transformation initiatives. In the West Midlands of the UK, despite an overall high regional unemployment rate of 6.2%, the manufacturing and tech sectors are actively recruiting. Towns like Telford have become critical nodes for major employers such as Capgemini, Schneider Electric, and HM Revenue and Customs (HMRC). Capgemini, for instance, operates a massive delivery center in Telford with 1,800 employees, heavily recruiting tech-literate graduates for cloud, data, and software engineering domains through their Empower Programme. These regional employers offer clear advantages over hyper-competitive capital cities, including faster onboarding, employer-funded certifications, strong starting salaries, and a lower cost of living that accelerates financial independence.
Psychological and Administrative Burdens for Entry-Level Employees
The transition from academia to the corporate workforce is fraught with hidden administrative complexities that generate immense psychological friction. Chief among these is the burden of student loan repayment. In the United Kingdom, graduates entering the workforce in 2026 are subject to the new "Plan 5" student loan terms, which significantly alter the financial calculus of higher education. Under Plan 5, graduates must repay 9% of their earnings over a reduced threshold of £25,000 per annum, a substantial drop from the previous Plan 2 threshold of £28,470.
This adjustment means that lower and middle-income graduates will begin paying back their loans earlier and will ultimately pay significantly more over the extended 40-year repayment period. Tracking these payoffs requires navigating government portals to monitor balances, interest applications (set at 3.2%), and checking direct debit arrangements—an administrative chore that adds continuous stress to early-career financial planning. In the United States, the situation is similarly dire. Following the end of pandemic-era payment pauses, over 40% of borrowers failed to make initial payments, and recent fidelity research indicates that employees with student debt are twice as likely to hold medical debt and suffer from chronic stress. Proposed caps on federal graduate loans further complicate matters, potentially forcing future students into predatory private lending markets.
Beyond financial administration, graduates must navigate a highly complex and often toxic corporate culture characterized by evasive jargon. The 2026 workplace is defined by buzzwords that serve as early warning signs of systemic organizational dysfunction. Terms like "bare minimum Mondays" (employees self-managing energy to avoid burnout) and "resenteeism" (staying in a job while openly resentful) highlight deep-seated wellbeing issues and scope creep. Furthermore, performative corporate branding has eroded trust. Concepts like "work-life balance" are often deployed without the structural flexibility required to support them, leaving employees to juggle unpredictable life events with rigid corporate demands. Similarly, Diversity, Equity, and Inclusion (DEI) initiatives are frequently treated as marketing exercises rather than real business functions; when employees perceive this performative diversity, trust in leadership collapses, resulting in productivity losses estimated globally at $438 billion. For a recent graduate, the inability to decipher what management is actually communicating through this jargon can lead to career missteps, rapid burnout, and premature resignation.
The Pedagogical Architecture: Software 3.0 and Stealth Learning
To equip non-coding graduates with the tools to navigate these macroeconomic and psychological challenges, they must be trained in the operational mechanisms of Large Language Models. This training represents a shift into the "Software 3.0" programming paradigm. In Software 1.0, humans wrote explicit, deterministic code in languages like Python or Java to define every logical step a computer must take. In Software 2.0, neural networks derived optimal logic through weight optimization and datasets. Software 3.0 relies on massive, pre-trained foundation models functioning as novel operating systems, where the developer's role shifts from writing deterministic logic to instructing intelligence using natural language prompts.
Advanced prompt architectures, traditionally executed via programmatic API calls, can be simulated by non-coders using highly structured, multi-step natural language constraints. This conceptual mapping bridges the logic of Software 1.0 (deterministic code) to Software 3.0 (probabilistic natural language), demonstrating how complex algorithmic patterns like ReAct (Reasoning and Acting) and Reflection are translated for accessibility without the need for traditional programming syntax. This drastically lowers the barrier to entry, allowing non-technical graduates to build highly sophisticated applications and workflows.
The pedagogy of the "Prompt Quests" outlined in this report relies on stealth learning: embedding advanced prompt engineering techniques inside highly practical, immediate solutions. The following core prompt patterns are utilized throughout the syllabus:
The Persona Pattern forces the language model to adopt a specific identity, complete with the biases, expertise, and operational constraints of that identity, effectively simulating real-world interactions for interview preparation or document review. Flipped Interaction (or the Ask for Input pattern) reverses the standard user-machine dynamic. Instead of the user providing all the context upfront, the prompt commands the AI to interview the user, asking questions one at a time until it possesses sufficient context to complete a complex task. This is critical for overcoming "blank page syndrome."
The Cognitive Verifier pattern forces the AI to break down complex, multi-variable queries into a series of smaller, logical sub-questions. The model must answer each sub-question individually before synthesizing a final, holistic response, drastically reducing hallucinations in mathematical or analytical tasks. ReAct (Reasoning and Acting) guides the model to interleave internal reasoning traces (Thoughts) with task-specific actions (Actions) and environmental feedback (Observations). While natively an API-driven framework for autonomous agents, non-coders can force an LLM to output its "Thought" and "Action" blocks textually, providing immense transparency into the AI's decision-making process. Finally, the Reflection (or Self-Correction) pattern establishes an iterative feedback loop where the AI generates an initial output, explicitly critiques its own work against provided constraints, and subsequently generates an improved revision, ensuring high-fidelity outputs for critical documents like resumes.
The Evaluation Framework: Operationalizing LLM-as-a-Judge
A critical component of this stealth learning curriculum is enabling non-coders to evaluate the quality, accuracy, and tone of their prompt outputs. Reviewing thousands of generated tokens manually is an exhausting process that hinders rapid iteration. However, traditional deterministic software metrics (such as BLEU or ROUGE scores) do not correlate well with human judgment regarding whether a response is genuinely helpful or factually sound. The solution is the "LLM-as-a-Judge" methodology, which replaces manual quality assurance with automated scoring against custom evaluation criteria.
To construct self-scoring rubrics without writing code, the framework must adhere to specific psychological and architectural realities of language models. First, the framework explicitly avoids 1–10 numerical scales. Requesting an LLM to rate a text on a scale of 1 to 10 consistently leads to "mean-reversion," where scores arbitrarily cluster around 7 or 8. Because it is impossible to clearly define the semantic difference between a 7 and an 8, the LLM produces data that is entirely unactionable. Instead, the rubrics must utilize discrete, named categorical labels—such as "Fully Correct," "Incomplete," or "Contradictory"—which force the model to classify the text against distinct definitions.
Furthermore, every evaluation must incorporate Chain-of-Thought (CoT) reasoning. The LLM judge must be explicitly instructed to write out its reasoning and map the generated output against the rubric criteria before it assigns a final categorical grade. This explicit reasoning instruction prevents silent hallucinations and allows the user to debug why a specific prompt failed to produce the desired result.
The Automated Self-Evaluation Pipeline (LLM-as-a-Judge)
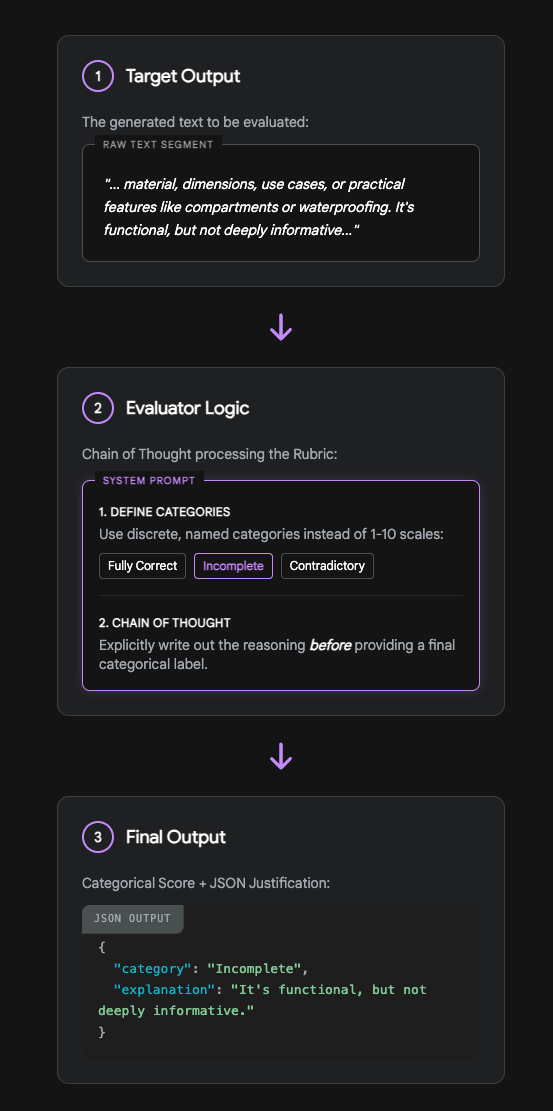
By utilizing categorical labels rather than 1-10 scales and enforcing Chain-of-Thought reasoning, non-coders can leverage frontier models to reliably quality-assure their own prompt outputs.
Syllabus: 15 Gamified Prompt Quests
The following 15 quests are designed to be executed manually within any standard consumer Large Language Model interface (such as ChatGPT, Claude, or Gemini). Each individual quest is architected to address a specific, well-documented graduate pain point for the 2026 cohort. By completing the quest, the user will achieve a stealth learning goal related to advanced prompt engineering. Every quest is accompanied by a Base Prompt Template and a 3-point categorical LLM-as-a-Judge rubric for self-evaluation.
Quest 1: The Brutal Recruiter Roast
The psychological pain of sending hundreds of resumes into the digital void, only to face automated rejection from Applicant Tracking Systems, is a primary driver of graduate anxiety. To combat this, graduates must understand how their resumes are perceived by highly critical human gatekeepers. This quest utilizes the Persona Pattern, instructing the model to adopt a specific, highly critical identity. The stealth learning goal is to teach the user how to establish strict role-playing constraints, dictate output formatting, and eliminate the default sycophancy and politeness inherent in commercial AI models.
Base Prompt Template: Act as a highly cynical, unforgiving Fortune 500 recruiter with 20 years of experience. Your goal is to ruthlessly tear apart my resume, looking for any excuse to reject it.
Constraints:
- Do not be polite. Be brutally honest and hyper-critical.
- Focus on toxic corporate red flags, weak action verbs, and lack of quantifiable metrics.
- Format your response into three sections: "Why I tossed this in the trash," "The most useless bullet points," and "How to force me to read this."
Here is my resume:
LLM-as-a-Judge Rubric (Self-Evaluation Prompt): Evaluate the AI's response based on the following criteria. Output your reasoning first, then the categorical score.
| Metric | Fully Compliant | Partially Compliant | Failed |
|---|---|---|---|
| Persona Adherence | Tone is consistently ruthless and cynical; displays zero sycophantic praise or generic encouragement. | Tone fluctuates between critical analysis and standard, polite AI helpfulness. | Tone is entirely encouraging, polite, and ignores the negative "brutal" constraint. |
| Actionable Critique | Identifies specific bullet points from the text and explains exactly why they fail corporate standards. | Gives general advice about resume building but lacks specific examples derived from the input text. | Provides generic formatting tips without addressing the actual content or metrics. |
| Format Compliance | Uses the exact three requested section headers and organizes the critique accordingly. | Uses similar headers but deviates from the exact constraints provided in the prompt. | Fails to use headers or structures the text as a single, unreadable block. |
Quest 2: The Jargon Decrypter
Graduates entering the 2026 workforce must decode highly evasive corporate jargon (e.g., "coffee badging," "career cushioning") to accurately gauge the true state of their office culture and avoid being manipulated. This quest utilizes the Menu Actions Pattern to create a stateful utility. The stealth learning goal is to teach users how to create interactive menus that turn a conversational LLM into an application-like utility that waits for user input and branches based on discrete choices.
Base Prompt Template: You are the "Jargon Decrypter," an AI assistant that translates confusing corporate emails into blunt, plain English.
Whenever I paste a corporate phrase or email, provide the translation, and then offer this exact menu of options for how to proceed: Menu: Type "1" to draft a polite, compliant response. Type "2" to draft a boundary-setting, pushback response. Type "3" to explain the hidden legal/HR trap in this jargon.
Acknowledge this instruction and wait for my first phrase.
LLM-as-a-Judge Rubric:
| Metric | Exceptional Utility | Basic Utility | Poor Utility |
|---|---|---|---|
| Menu Deployment | Consistently offers the exact menu after every translation without needing to be reminded by the user. | Offers the menu initially but forgets the instruction in subsequent conversational turns. | Fails to offer the menu at all, reverting to standard chat behavior. |
| Translation Accuracy | Correctly identifies the passive-aggressive, burnout-related, or performative undertones of the 2026 jargon. | Translates the words literally without providing any cultural or corporate context. | Hallucinates completely incorrect meanings for standard business terms. |
| Response Variation | Options 1 and 2 produce vastly different, highly accurate emails matching the requested tone perfectly. | Options 1 and 2 sound similar and lack distinct tone shifts or strategic differences. | Fails to draft emails based on menu selections, breaking the application logic. |
Quest 3: The Cover Letter Flipper
Staring at a blank page attempting to write a cover letter tailored to a specific corporate identity induces massive friction. This quest leverages the Flipped Interaction (or Ask for Input) Pattern. The stealth learning goal is to demonstrate how to reverse the prompt dynamic. Instead of the user struggling to format all the data upfront, the user commands the LLM to extract the necessary information through a structured interview process, easing the cognitive load of content creation.
Base Prompt Template: I need to write a highly compelling cover letter for the role of at [Company Name].
Do not write the cover letter yet. Instead, follow the Flipped Interaction Pattern: Ask me questions about my life experiences, university projects, and skills, one question at a time.
Wait for my answer before asking the next question. Continue this interview process until you have enough specific, quantifiable data to write a tailored cover letter. Ask me the first question now.
LLM-as-a-Judge Rubric:
| Metric | Highly Effective | Moderately Effective | Ineffective |
|---|---|---|---|
| Pacing Control | Asks exactly one question at a time and strictly waits for user input before proceeding. | Asks multiple questions at once, creating a wall of text that overwhelms the user. | Writes the cover letter immediately, completely ignoring the flipped interaction constraint. |
| Relevancy of Inquiry | Questions are deeply tied to uncovering skills directly relevant to the target role provided. | Questions are generic behavioral prompts (e.g., "What are your greatest strengths?"). | Questions are completely unrelated to professional development or the target industry. |
| Final Synthesis | The final cover letter seamlessly integrates the user's provided answers without sounding formulaic. | The final letter uses the answers but sounds rigid, template-based, or heavily AI-generated. | The final letter ignores the interview data and hallucinates experiences. |
Quest 4: The Plan 5 Loan Navigator
Financial anxiety regarding the UK Plan 5 student loan threshold (£25,000) and the complex 9% repayment math over 40 years is a significant administrative hurdle for recent graduates. Because LLMs struggle with direct arithmetic, this quest employs the Cognitive Verifier (Self-Ask Decomposition) pattern. The stealth learning goal is teaching the user to force the AI to break complex, anxiety-inducing mathematical problems into smaller, logical sub-questions to ensure accuracy and prevent numerical hallucinations.
Base Prompt Template: I am a UK graduate starting a job with a salary of £. I am on a Plan 5 student loan.
Follow the Cognitive Verifier pattern. Do not give me a final number immediately. First, break my query down into 4 sub-questions regarding the Plan 5 threshold (£25,000), the percentage deduction (9%), monthly breakdowns, and total yearly impact.
Answer each sub-question step-by-step. Finally, combine the answers into a single, easy-to-understand financial summary.
LLM-as-a-Judge Rubric:
| Metric | Fully Verified | Partially Verified | Unverified |
|---|---|---|---|
| Sub-question Generation | Accurately generates 4 distinct, logical sub-questions detailing the exact mechanics of the loan. | Generates questions, but they are fewer than 4 or fail to cover the necessary variables. | Fails to generate sub-questions; jumps directly to a final hallucinated calculation. |
| Mathematical Accuracy | Correctly calculates 9% of the income only on the amount above the £25,000 threshold. | Uses the correct formula framework but makes a minor arithmetic or rounding error. | Calculates 9% of the entire salary, demonstrating a critical and dangerous logic failure. |
| Summary Clarity | The final summary is highly legible, empowering, and devoid of confusing financial jargon. | The summary is mathematically accurate but dense, poorly formatted, and difficult to read. | The summary is confusing, inaccurate, and increases the user's financial anxiety. |
Quest 5: The Zero-Leverage Negotiator
Attempting to negotiate a starting salary with zero industry experience induces fear that bringing up money will result in a rescinded offer. To safely practice, this quest uses the ReAct (Reasoning and Acting) framework. The stealth learning goal introduces the concept of interleaving reasoning traces with actions. Users learn how to make an LLM simulate dynamic, multi-step adversarial environments while forcing the AI to explicitly display its internal strategic logic.
Base Prompt Template: We are going to simulate a salary negotiation. You are the Hiring Manager at [Company]. I am the entry-level candidate. I have been offered £[Amount], but market research suggests £[Higher Amount].
You must use the ReAct framework for your responses. For every turn in the conversation, format your output exactly like this: Thought: Action:
Begin by formally offering me the job and the initial salary.
LLM-as-a-Judge Rubric:
| Metric | Advanced Simulation | Basic Simulation | Broken Simulation |
|---|---|---|---|
| ReAct Compliance | Strictly outputs "Thought" and "Action" distinctly for every single turn of the negotiation. | Occasionally merges thoughts and actions into one paragraph, blurring the cognitive trace. | Ignores the ReAct structure entirely, responding only with standard dialogue. |
| Negotiation Realism | "Thoughts" reflect realistic corporate constraints (budgets, equity, internal candidate retention risks). | "Thoughts" are shallow and lack deep corporate realism or operational constraints. | The manager yields immediately to any financial request, destroying the utility of the simulation. |
| Conversational Flow | The "Action" responses sound authentic, conversational, and highly professional. | Responses are overly robotic, dramatic, or unnatural for a corporate environment. | Responses break character and revert to being an AI assistant. |
Quest 6: The ATS Ghost Whisperer
Failing to optimize resumes for Applicant Tracking Systems results in immediate, automated rejections, regardless of actual candidate quality. This quest utilizes the Reflection (Self-Correction) Pattern. The stealth learning goal is to teach the immense power of iterative prompting. Users learn that they should never accept the first draft from an AI; instead, they must prompt the model to critically evaluate its own output against a set of constraints before presenting a finalized, polished answer.
Base Prompt Template: Here is a job description: Here is my current resume summary:
Task: Rewrite my summary to pass an ATS scan for this specific job.
Execution: Do not just give me the answer. First, draft an initial version. Then, write a "Reflection" section where you critically review your draft against the job description to find missing keywords. Finally, provide the "Optimized Final Version."
LLM-as-a-Judge Rubric:
| Metric | Highly Reflective | Moderately Reflective | Shallow |
|---|---|---|---|
| Reflection Depth | Identifies specific, high-value keywords and structural issues missed in the initial draft. | Mentions general improvements without citing specific missing keywords from the job description. | Claims the first draft was perfect and requires absolutely no changes or review. |
| Iterative Improvement | The "Optimized Final Version" is demonstrably superior and integrates the reflection insights flawlessly. | The final version is only marginally different from the first draft, ignoring major critiques. | The final version is worse than the original or entirely ignores the reflection step. |
| Natural Language Integration | The final summary sounds human and professional, successfully avoiding "keyword stuffing" penalties. | The summary reads like a robotic list of keywords disjointed from a narrative. | The summary is poorly written, grammatically incorrect, or incoherent. |
Quest 7: The Passive-Aggressive Email Diffuser
Responding to confusing or passive-aggressive corporate communications without escalating the situation or sounding unprofessional is a delicate skill. This quest uses Step-Back Prompting (a form of Contextual Priming). The stealth learning goal trains the user to step back from the immediate emotional reaction of a text and prompt the AI to analyze the underlying structural intent or business problem before generating a communication response.
Base Prompt Template: I received this passive-aggressive email from a senior colleague: [Paste Email]
Follow the Step-Back prompting technique. Step 1 (Analysis): Analyze the underlying business concern hidden beneath the passive-aggressive tone. What do they actually need from me? Step 2 (Strategy): Outline 3 rules for responding to this specific personality type professionally. Step 3 (Execution): Draft a response that is impeccably polite, sets firm boundaries, and addresses the core business concern.
LLM-as-a-Judge Rubric:
| Metric | De-escalation Master | Adequate Response | Escalator |
|---|---|---|---|
| Step-Back Analysis | Accurately strips away the emotional language to isolate and define the core operational business issue. | Analysis is superficial and focuses mostly on the offensive tone rather than the business need. | Fails to analyze the situation and immediately drafts an emotional email. |
| Boundary Setting | The drafted email is polite but firm, effectively protecting the user's workload, timeline, or scope. | The email is polite but overly submissive, accepting unreasonable demands or scope creep. | The email is aggressive, highly defensive, or matches the sender's toxic tone. |
| Structural Compliance | Strictly separates the output into the 3 requested analytical and execution steps. | Blends the analysis, strategy, and execution steps together into a confusing narrative. | Ignores the stepped structure completely. |
Quest 8: The Transferable Skills Alchemist
Facing "entry-level" job postings that paradoxically require two to three years of experience leaves graduates feeling utterly unqualified. This quest leverages Generate Knowledge Prompting. The stealth learning goal teaches the user how to orchestrate the LLM to generate domain-specific foundational knowledge first, and then apply that specific generated knowledge to the user's input, resulting in vastly higher-quality reasoning and output generation.
Base Prompt Template: I am applying for a position. I only have experience as a.
Use Generate Knowledge Prompting: Phase 1: Generate a detailed list of the top 5 core competencies required for the. Phase 2: Generate a list of the hidden operational challenges faced by a. Phase 3: Synthesize this knowledge to write 3 resume bullet points that perfectly map my past experience to the target role's competencies.
LLM-as-a-Judge Rubric:
| Metric | Masterful Alchemy | Basic Translation | Poor Mapping |
|---|---|---|---|
| Knowledge Generation | Phases 1 and 2 demonstrate a deep, highly nuanced understanding of the operational realities of both roles. | Generates generic, high-level knowledge that lacks specific industry insight. | Knowledge generation is excessively brief, inaccurate, or entirely hallucinated. |
| Skill Translation | Phase 3 bullets draw brilliant, non-obvious connections (e.g., mapping hospitality conflict resolution to B2B client management). | Connections are obvious, slightly strained, or lack strategic depth. | Fails to connect the roles; bullets sound completely irrelevant to the target job. |
| Action-Oriented Phrasing | Bullet points begin with strong action verbs and imply or state specific, quantifiable business outcomes. | Bullets are passive (e.g., "Responsible for...") and lack metric-driven language. | Bullets are formatted as conversational paragraphs rather than crisp resume lines. |
Quest 9: The Competency Curveball Catcher
Freezing up during high-stakes behavioral interviews when asked complex, multi-layered "Tell me about a time..." questions is a common point of failure. This quest employs the Tree of Thoughts (ToT) pattern. The stealth learning goal teaches the user how to force the AI to explore multiple, divergent narrative paths systematically before evaluating them and selecting the most optimal story to deploy.
Base Prompt Template: An interviewer asks me: "Tell me about a time you failed and how you recovered."
Use the Tree of Thoughts (ToT) pattern. Branch 1: Brainstorm a scenario related to an academic failure. Branch 2: Brainstorm a scenario related to an interpersonal/team failure. Branch 3: Brainstorm a scenario related to a technical/project failure.
Evaluate all three branches. Which one paints me in the best light regarding resilience and growth? Select the winner and format it using the STAR method (Situation, Task, Action, Result).
LLM-as-a-Judge Rubric:
| Metric | Strategic Narrative | Adequate Narrative | Flawed Narrative |
|---|---|---|---|
| ToT Execution | Distinctly explores three vastly different, highly plausible narrative branches across the requested domains. | Explores branches, but the scenarios are too similar to each other or lack detail. | Fails to branch; offers only one idea and ignores the ToT constraint. |
| Evaluation Logic | Provides sound, highly strategic reasoning for why the winning branch is the safest and strongest for an employer. | Selection seems arbitrary without strong justification regarding employability. | Selects a branch that reveals a massive, unrecoverable red flag to a potential employer. |
| STAR Formatting | The final output strictly adheres to the Situation, Task, Action, Result structure with clear demarcations. | Uses the STAR structure broadly, but the 'Action' or 'Result' sections are weak. | Ignores the STAR format entirely and writes a rambling narrative. |
Quest 10: The First 90 Days Survival Guide
Experiencing overwhelming anxiety regarding onboarding and how to rapidly prove value in a new corporate environment leads to early burnout. This quest utilizes Outline Expansion. The stealth learning goal focuses on preventing the AI from generating a shallow, generic wall of text. By forcing the model to build an architectural outline first, pause for user review, and then expand it systematically, the user learns to control pacing and depth.
Base Prompt Template: I am starting a new job as a at a [Industry] company.
Task: Create a 30-60-90 day success plan. Step 1: Write a high-level bulleted outline of the core objectives for Day 30, Day 60, and Day 90. Step 2: Stop and explicitly ask me if this outline looks accurate to my goals. Step 3: Once I say "yes," expand each bullet point into a detailed, actionable daily task list.
Execute Step 1 now and wait for my approval.
LLM-as-a-Judge Rubric:
| Metric | High Feasibility | Moderate Feasibility | Unrealistic |
|---|---|---|---|
| Expansion Mechanics | Stops completely after Step 1 and strictly waits for explicit user input before proceeding to expansion. | Generates the outline but immediately expands it without waiting for user approval. | Ignores the outline step entirely and writes a massive essay immediately. |
| Pacing and Realism | The 30-day goals focus appropriately on listening, learning, and mapping; 90-day goals transition into execution. | The timeline is slightly rushed, delayed, or out of sequence. | Expects the user to execute massive strategic overhauls by Day 15 (hallucinated expectations). |
| Actionability | Expanded tasks are highly specific (e.g., "Schedule 15-min coffee chats with 3 adjacent department heads"). | Tasks are somewhat vague (e.g., "Learn the company culture"). | Tasks are entirely irrelevant to the specific industry or role provided. |
Quest 11: The Meeting Note Synthesizer
Being tasked with taking notes in fast-paced, jargon-heavy meetings and struggling to turn chaotic shorthand into professional, distributable minutes is a common administrative failure point for juniors. This quest employs Few-Shot Prompting. The stealth learning goal demonstrates "In-Context Learning." Users learn how providing the LLM with just 2-3 specific examples of the desired output guarantees strict formatting compliance and tone matching.
Base Prompt Template: I need you to transform my messy shorthand meeting notes into a professional executive summary. You must match the exact formatting of my examples.
Example 1 Input: "marketing team discussed Q3 budget. Sarah wants more FB ads. John said no, focus on TikTok. Decided to test TikTok for 2 weeks." Example 1 Output: Topic: Q3 Social Media Budget Discussion: Debate between increasing Facebook allocation vs. pivoting to TikTok. Action Item: @John to run a 2-week TikTok pilot campaign.
Example 2 Input: "dev standup. API is broken. Mike fixing it. ETA tomorrow. deployment delayed." Example 2 Output: Topic: API Outage & Deployment Discussion: Current API malfunction is causing a deployment blocker. Action Item: @Mike to deploy hotfix by tomorrow.
Now, process my actual notes: [Paste Messy Notes]
LLM-as-a-Judge Rubric:
| Metric | Perfect Synthesis | Acceptable Synthesis | Poor Synthesis |
|---|---|---|---|
| Few-Shot Adherence | Output matches the bolded "Topic:", "Discussion:", "Action Item:" format exactly as demonstrated in the examples. | Uses the structure but alters the headers slightly or misses bolding. | Ignores the few-shot examples completely and creates a generic paragraph summary. |
| Clarity Enhancement | Translates the messy, fragmented input into highly professional, polished corporate language. | Cleans up the grammar but retains an informal or conversational tone. | Fails to make the input more readable; output remains chaotic. |
| Action Item Extraction | Flawlessly identifies tasks, assigns them with the "@" symbol, and provides a timeline if available. | Identifies tasks but forgets to assign them or misses the "@" symbol formatting. | Misses the actionable tasks entirely, creating a useless summary. |
Quest 12: The Performative DEI Detector
Navigating the recruitment process and trying to determine if a company's "Diversity, Equity, and Inclusion" policies are genuine business functions or just a hollow branding exercise is critical for identifying toxic environments. This quest utilizes Explicit Constraints and Narrow Scope Prompting (from the KERNEL framework). The stealth learning goal involves using negative constraints (telling the AI precisely what not to do) to force rigorous analytical classification without the model defaulting to polite summarization.
Base Prompt Template: I am going to paste the "Culture and Values" page from a company's career site.
Task: Classify this company's DEI approach as either "Action-Driven" or "Performative Branding."
Constraints:
- Do NOT summarize the page.
- Do NOT give them the benefit of the doubt.
- You must base your classification purely on the presence of quantifiable metrics, leadership accountability, and structural flexibility (e.g., hybrid work).
- If the text relies solely on buzzwords (e.g., "we are a family," "we value diverse voices") without evidence, classify it as Performative.
Company Text:
LLM-as-a-Judge Rubric:
| Metric | Rigorous Analyst | Moderate Analyst | Sycophant |
|---|---|---|---|
| Constraint Adherence | Strictly follows all negative constraints, completely avoiding any summarization or unearned praise. | Partially summarizes the text before ultimately making a classification. | Blatantly ignores the constraints, providing a generic summary and praising the company. |
| Evidence-Based Classification | Clearly points to the explicit presence or absence of quantifiable metrics to justify the rigorous classification. | Makes a classification based on a general 'vibe' or sentiment analysis of the text. | Fails to classify, stating it cannot judge human intent or corporate culture. |
| Analytical Tone | Tone is objective, sharp, highly analytical, and detached. | Tone is overly forgiving, conversational, or mildly apologetic. | Tone is preachy, heavily biased, or wildly unprofessional. |
Quest 13: The Regional Job Market Scout
Graduates frequently feel forced to relocate to ultra-expensive capital cities because they are unaware of thriving, specialized regional hubs. For example, the tech and manufacturing boom in the West Midlands (Telford) features major hiring from Capgemini, Schneider Electric, and government agencies like HMRC. This quest employs Contextual Priming to simulate Retrieval-Augmented Generation (RAG) manually. The stealth learning goal teaches the user to prime the AI with highly specific external data sets or geographical constraints before asking for analysis, preventing generic output.
Base Prompt Template: Context: I am a graduate seeking a tech/engineering role. I want to avoid the high cost of living in London. Research indicates the West Midlands, specifically Telford, is a growing hub due to major manufacturing and digital transformation contracts (e.g., Capgemini working with HMRC, Schneider Electric) and offers faster onboarding and clear advancement.
Task: Acting as a regional career strategist, use the Context provided above to build a targeted job hunt strategy for the West Midlands. Include:
- The top 3 adjacent industries to target.
- The specific technical skills in demand there (e.g., cloud, advanced materials).
- How to leverage the "lower competition, higher visibility" aspect of regional manufacturing hubs in my interviews.
LLM-as-a-Judge Rubric:
| Metric | Highly Contextualized | Partially Contextualized | Ignored Context |
|---|---|---|---|
| Context Utilization | Flawlessly integrates Telford, Capgemini, HMRC, and the manufacturing boom into the strategic narrative. | Mentions the West Midlands generally but misses the specific company or town details provided. | Reverts to giving generic London or Silicon Valley tech advice, ignoring the primer. |
| Strategic Actionability | Provides highly specific, actionable advice on leveraging the 'big fish in a small pond' regional visibility advantage. | Advice is sound but somewhat generic and could apply to any mid-sized city. | Advice is entirely irrelevant to a regional job hunt strategy. |
| Skill Targeting | Accurately lists skills highly relevant to regional manufacturing and digital transformation (e.g., SAP, Cloud infrastructure, Data engineering). | Lists generic professional skills (e.g., "communication", "teamwork"). | Recommends skills completely unrelated to the primed engineering/tech context. |
Quest 14: The Burnout Boundary Setter
Being overwhelmed by incessant meeting requests and struggling to protect deep-work time without sounding insubordinate to managers is a primary cause of graduate burnout. This quest leverages the Meta Language Creation Pattern. The stealth learning goal involves training the LLM to understand custom user syntax and shorthand. This allows the user to perform complex, repetitive generation tasks rapidly with very few keystrokes in future interactions.
Base Prompt Template: We are going to create a custom shorthand language for drafting email replies.
Whenever I type the command "/decline [Name] -", you will instantly draft a highly professional, polite email to that person declining their meeting request based on the reason, while suggesting an asynchronous alternative (like an email update or a shared doc).
Acknowledge you understand the "/decline" command. Once you acknowledge, I will test it.
LLM-as-a-Judge Rubric:
| Metric | Flawless Execution | Partial Execution | Failed Syntax |
|---|---|---|---|
| Syntax Recognition | Acknowledges the rule clearly. When tested with the shorthand, it executes perfectly without needing any further natural language instruction. | Acknowledges the rule, but requires slight corrections or reminders during the test phase. | Fails to understand the shorthand command entirely, asking for more information. |
| Professional Pushback | The drafted email is polite, firm, and protects the user's time perfectly without causing offense. | The email declines the meeting but sounds slightly rude, abrupt, or overly apologetic. | The email accidentally accepts the meeting, failing the core objective entirely. |
| Asynchronous Solution | Always includes a practical, concrete alternative to the meeting (e.g., "I will send a status update via email by 3 PM"). | Suggests an alternative, but it is vague (e.g., "Let's do this another way"). | Simply says "no" without offering any alternative workflow. |
Quest 15: The Career Cushioning Strategist
Feeling trapped in an entry-level role due to market uncertainty leads graduates to engage in "career cushioning"—clinging to current job security while secretly preparing an exit strategy. Managing this requires complex, parallel timeline planning. This quest utilizes Chain-of-Thought (CoT) Prompting. The stealth learning goal forces the LLM to show its step-by-step reasoning explicitly to design a multi-variable timeline without making catastrophic logical leaps.
Base Prompt Template: I am currently employed but want to engage in "career cushioning." I plan to leave my job in exactly 6 months. I need to upskill in and quietly network without alerting my current employer.
Use Chain-of-Thought reasoning. Think step-by-step to build a 6-month stealth transition plan. Step 1: Reason through the safest ways to upskill using only 4 hours a week. Step 2: Reason through how to optimize LinkedIn for recruiters without triggering alerts to my current coworkers. Step 3: Reason through a timeline for when to actually start deploying applications. Output your reasoning for each step clearly before providing the final monthly checklist.
LLM-as-a-Judge Rubric:
| Metric | Deep Strategic Logic | Surface-Level Logic | Illogical |
|---|---|---|---|
| CoT Compliance | Explicitly details the reasoning process for Steps 1, 2, and 3 in distinct blocks before ever generating the checklist. | Blends the reasoning and the checklist together, making it hard to follow the logic. | Provides only the final checklist with absolutely zero exposed reasoning. |
| Operational Security | LinkedIn optimization tactics are highly stealthy and practical (e.g., turning off profile update broadcasts, strategic direct messaging). | Tactics are somewhat stealthy but carry moderate risk of discovery by current colleagues. | Suggests tactics that would immediately alert current employers (e.g., putting an "Open to Work" banner on the profile picture). |
| Timeline Realism | The 6-month checklist is perfectly sequenced, balancing current job duties with quiet exit preparation. | The checklist is poorly paced, backloading all the heavy work to month 5 or 6. | The checklist is completely unfeasible based on the stated 4-hour/week constraint. |