
The landscape of business-to-business (B2B) content distribution has fundamentally fractured, evolving into a highly complex, algorithmic ecosystem that ruthlessly filters out generic corporate communications. The proliferation of generative artificial intelligence has resulted in an exponential increase in high-volume, low-friction content—widely referred to within industry and marketing circles as "corporate slop" or "AI slop". 1 Consequently, professional audiences have developed sophisticated algorithmic and psychological filters to ignore perfectly polished, overly optimized, and hyper-positive content. To capture meaningful attention in this saturated and skeptical environment, a system cannot merely generate grammatically correct text; it must operationalize authenticity, strategic vulnerability, and highly specific human experiences.
The concept of the "Walking Ghostwriter" (here's the PLAUD AI Notepin) —an AI agentic ecosystem designed to seamlessly ingest raw, unstructured, stream-of-consciousness audio transcripts captured during a founder's daily routine and autonomously output highly nuanced, algorithmically optimized LinkedIn narratives—represents the bleeding edge of cognitive externalization and marketing automation. This architecture moves beyond simple "prompt engineering" into the realm of stateful, multi-agent systems equipped with long-term memory structures. This comprehensive research report delineates the exhaustive systems architecture required to build, deploy, and scale this pipeline. It systematically covers the algorithmic anatomy of modern virality, visual and media positioning strategies, the architectural design of a multi-template semantic style matrix, the rigorous protocols for integrating a temporal knowledge graph (Supermemory), the exact multi-agent execution workflow, and the advanced mechanisms for continuous, autonomous self-improvement.
1. The Algorithmic and Psychological Anatomy of Virality (2025–2026 Landscape)
To architect an effective generative agent, one must first deeply understand the environmental constraints and the underlying reward functions of the target distribution platform. As of the 2025 and 2026 operational cycles, the LinkedIn feed algorithm has transitioned away from a chronological and basic engagement-weighted system toward a unified, Large Language Model (LLM)-based retrieval pipeline. This architectural shift fundamentally alters how content is classified, evaluated, and distributed to professional networks.
1.1 The Shift to LLM-Based Unified Retrieval and the "Slop Tax"
The contemporary algorithmic reality prioritizes content that "knowledge members are likely to be interested in," strictly penalizing engagement-bait (explicitly asking for comments), videos paired with irrelevant text, and generic, template-based posts that regurgitate conventional industry wisdom without adding a novel perspective.
Crucially, the platform has integrated advanced spam detection and AI-pattern recognition algorithms capable of identifying automated, generic content creation with reported accuracies of up to 94%.11 AI-generated content that lacks a unique perspective, proprietary data, or a distinct human voice experiences severe algorithmic suppression.
| Content Characteristic | Algorithmic Impact | Platform Response |
|---|---|---|
| Highly Original/Human Perspective | Elevated Reach | Prioritized via LLM-based unified retrieval pipeline. |
| Generic "AI Slop" (Template-based) | -30% Reach Reduction | Deprioritized; 55% lower engagement rates reported. |
| Engagement-Bait Prompts | Active Suppression | Identified and aggressively filtered from primary feeds. |
| Automated "Pod" Engagement | Minimal to Negative | Ignored unless from highly relevant, historically interacting peers. |
The algorithm's primary currency is no longer the passive "like" or the automated comment. Instead, the system prioritizes "passive dwell time"—the exact duration a user spends reading a post or swiping through a document—and deep, meaningful engagement within specific professional niches.
1.2 The Psychology of the Founder Story: Weaponizing Vulnerability
The success of a founder's narrative hinges on psychological resonance rather than traditional corporate messaging. Standard B2B marketing relies heavily on positivity, success metrics, and polished case studies. However, extensive data analysis unequivocally demonstrates that "toxic positivity" is both algorithmically and psychologically punished in the modern feed.
An exhaustive analysis of nearly 2,000 top-performing posts reveals that content featuring mixed or negative sentiment—those openly discussing genuine operational struggles, critical strategic failures, or difficult realizations—enjoy a significant virality multiplier.
| Sentiment Classification | Virality Multiplier | Psychological Driver |
|---|---|---|
| Mixed / Negative (Vulnerable) | 1.34x | Cognitive dissonance, pattern interruption, authentic relatability. |
| Purely Positive (Corporate) | 0.98x | Viewed as synthetic advertising or boastful; easily ignored. |
The psychology underlying this phenomenon is rooted in cognitive dissonance and pattern interruption. In a feed hyper-saturated with synthesized success stories and AI-generated "thought leadership," an admission of failure or a raw, unpolished observation acts as a high-contrast focal point. It signals to the reader's subconscious that the subsequent text is authentic, human, and potentially contains hard-won, proprietary knowledge rather than recycled consensus. As noted by industry analysts, vulnerability is the ultimate competitive advantage because it represents an interpretation of the human experience—something an AI lacking a personal point of view cannot organically replicate.
1.3 Velocity and Distribution Mechanics
The temporal mechanics of platform distribution have also tightened considerably. The first 60 to 90 minutes post-publication are critical to a post's lifecycle. During this window, the algorithm tests the content with a micro-segment of the creator's immediate network to determine its initial "quality score" based on rapid engagement velocity. High early engagement signals quality, prompting the algorithm to progressively expand reach to second- and third-degree connections, creating exponential momentum.
Furthermore, publishing timing plays a crucial role in exploiting algorithmic vacuums. While standard business hours provide baseline visibility, analytical models indicate that off-peak hours—such as Tuesday at 1:00 AM or Thursday at 11:00 PM—often yield the highest virality multipliers due to drastically reduced feed competition, allowing a post to gain uninterrupted momentum before catching the wave of users waking up across global time zones.
1.4 The Call-to-Conversation (CTC) Architecture
Because thoughtful comments and shares carry substantially more algorithmic weight than simple likes, the generative agent must be programmed to end posts with a highly specific "Call-to-Conversation" (CTC) rather than a generic Call-to-Action.
Data strongly indicates that broad, closed-ended questions (e.g., "Thoughts?", "Do you agree?", or "Do you think job interviews are important?") fail to generate the type of meaningful interaction the algorithm rewards. A high-converting CTC must prompt the reader to share a personal narrative or access a specific, lived memory. For example, transitioning from a closed question to an open, experiential inquiry—such as "What is the worst piece of career advice you have ever received?" or "What decision will you make today that your future self will thank you for?"—shifts the psychological burden from a binary assessment to an experiential recall. This engineering of the post's conclusion is what drives the lengthy, high-quality comments that signal profound relevance to the LLM-based feed.
2. Visual and Media Positioning Strategy for Narrative Content
The visual component of a founder's post serves a singular, primary function: to arrest the user's scrolling behavior long enough for the textual hook to register cognitively. However, the strategy for a raw, narrative-driven founder who is intentionally rejecting "corporate slop" differs fundamentally from standard B2B visual guidelines.
2.1 The Rejection of Synthetic Polish and the "Vibe-Coded" AI
There is a proven inverse relationship between excessive visual polish and perceived authenticity in personal branding. Highly polished Canva graphics, generic stock photography, and explicitly AI-generated artwork (often termed "vibe-coded AI images") frequently create an invisible psychological barrier between the creator and the audience. Stock photos, for instance, average an abysmal 1.7 engagements per 1,000 followers. This occurs because these images trigger an "advertisement" schema in the viewer's brain, immediately prompting them to scroll past the content.
Conversely, raw authenticity performs exceptionally well in qualitative narrative posts. Surprisingly, deep data analysis shows that text-only posts (averaging 9.5 engagements per 1,000 followers) often outperform posts with generic images. When imagery is utilized for a vulnerable founder story, it should ideally be a genuine, unedited photograph—such as a blurry selfie taken during a walk, a raw screenshot of an internal data dashboard, or a simplistic text snippet on a plain background. These raw assets consistently outperform heavily branded templates because they reinforce the experiential, unfiltered nature of the accompanying text, signaling that a human, rather than a marketing department, authored the post.
2.2 The Algorithmic Dominance of the Document Carousel
While raw imagery is highly effective for personal narratives and "walking thoughts," educational updates, strategic frameworks, or complex business lessons require a fundamentally different vehicle. The Document Carousel (uploaded natively as a PDF) has emerged as the most algorithmically favored content format on the platform.
Because each swipe through a carousel slide counts as an active engagement metric and drastically increases overall dwell time, the algorithm aggressively amplifies this format above all others.
| Content Format | Average Engagement Rate (2025/2026) | Performance Multiplier |
|---|---|---|
| Carousels/Documents | 24.42% | 3.7x vs text 20 |
| Multi-images | 6.60% | Baseline |
| Native Video | 6.47% | Baseline 20 |
| Single Image | 6.05% | Baseline 20 |
| Text Only | 4.10% | Baseline 20 |
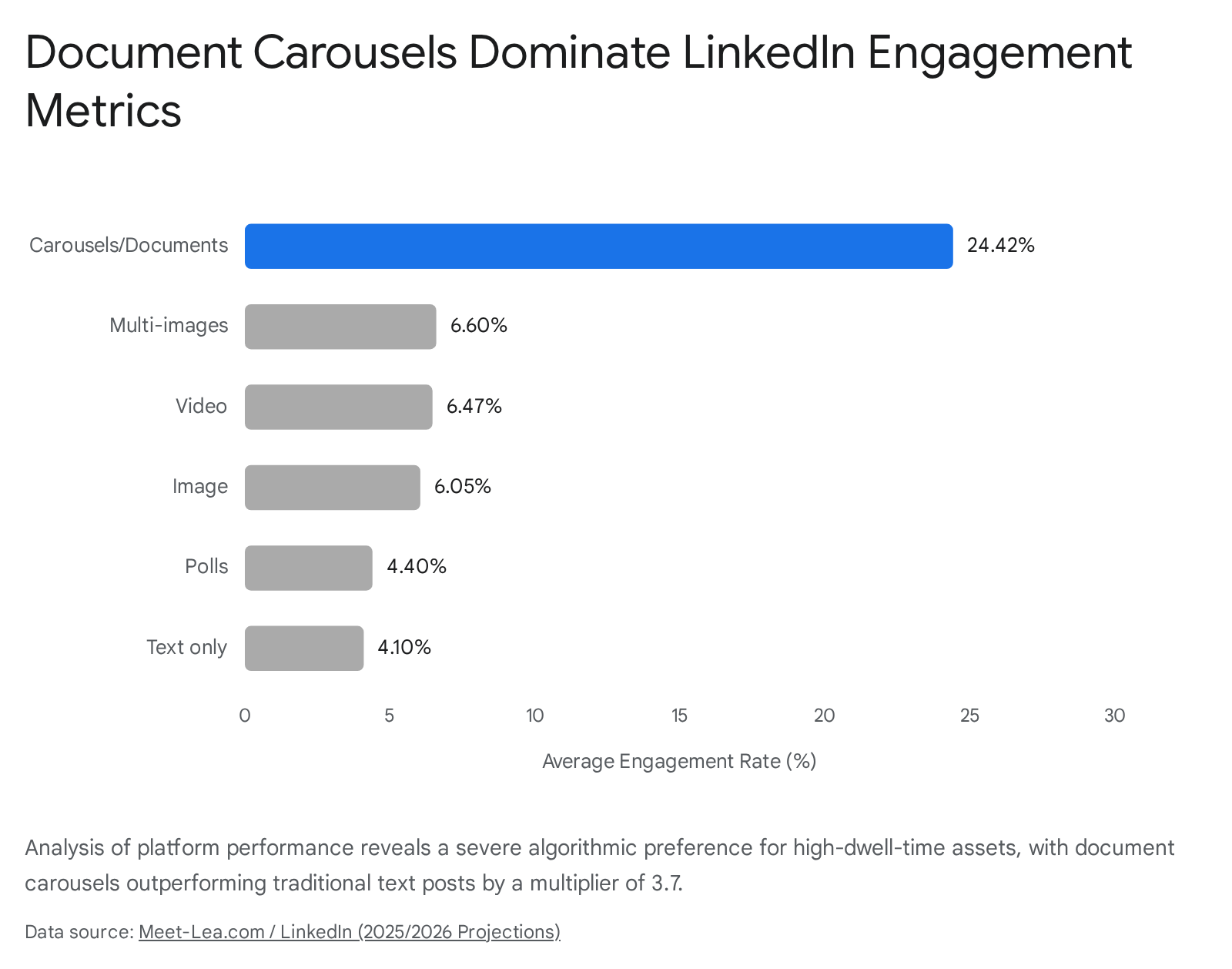
To optimize for this specific algorithmic preference, the AI agent must be programmed with rigorous design constraints for dynamically generating or formatting carousels when the transcript indicates a framework-style post:
- Dimensionality and Resolution: Carousels must be generated at a minimum of 300 DPI to ensure vector text remains crisp. The optimal dimensions are either 1080 x 1080 pixels (1:1 aspect ratio, standard square) or 1080 x 1350 pixels (4:5 aspect ratio, portrait), with the latter providing maximum screen real estate for mobile-first audiences, naturally generating higher dwell times.
- Pagination: While the platform permits up to 300 slides, data indicates that the optimal length for maintaining narrative momentum and maximizing engagement completion rates is between 5 and 15 slides.
- Structural Narrative Arc: The "cover slide + numbered list" formula is highly effective. The first slide must act as a visual hook, creating an immediate information gap or challenging a common belief. Subsequent slides must follow a logical narrative momentum, utilizing extreme brevity, ample white space, and bold visual cues (like arrows or progress indicators, e.g., "Step 3 of 5") to encourage continuous swiping.
- Format Constraints: The final output must be compiled into a high-quality PDF under 100MB; individual image uploads result in formatting errors and lower algorithmic prioritization. The system must utilize consistent brand colors, fonts (minimum 24pt for headers, 18pt for body text), and styling across all slides to ensure professional visual cohesion.
3. The Narrative "Style" Matrix: Architectural Blueprints for Generative AI
An autonomous content engine cannot rely on a single, monolithic prompt structure. Treating an LLM merely as a sophisticated auto-complete tool yields hollow, generic output that fails to capture the nuances of human reasoning and structural pacing. Instead, the system must employ advanced semantic routing to classify the raw audio transcript and intelligently map it to a specific, highly engineered structural template.
Before any template is applied, the AI agent must first load the founder's specific "Voice DNA." This should not be a loose, descriptive text prompt, but rather a robust, machine-readable JSON-LD schema that programmatically defines the user's linguistic patterns, exact phrasing tendencies, tone, and formatting preferences. This Voice DNA ensures that "slop signals"—such as the use of forbidden corporate clichés (e.g., "leverage synergies," "unlock value," "delve"), missing points of view, or vague benefit claims—are completely eradicated from the generation process.
Once the Voice DNA and the CRISP framework (Context, Role, Instruction, Structure, Parameters) parameters are loaded , the Strategy Agent evaluates the transcript against four distinct architectural blueprints to determine the optimal output structure.
3.1 Style Blueprint 1: The Vulnerable Bridge (The Mundane Metaphor)
This blueprint is the philosophical cornerstone of the "Walking Ghostwriter" pipeline. It takes a visceral, seemingly irrelevant detail from the creator's immediate physical reality (e.g., dodging traffic, experiencing bad weather, or the user's specific example of "kicking a poisonous mushroom in the lawn") and elegantly bridges it to a profound, often difficult business insight.
- The Hook (The Tension): The post must never open with industry data or product specifications. It must start in the middle of a story, leveraging physical action or an unusual setting to create immediate tension. The opening hook is strictly constrained to a dual-line, mobile-optimized format to ensure maximum scannability and scroll-stopping power.
- Example Execution: "I spent 10 minutes this morning kicking poisonous mushrooms out of my front lawn. It is exactly how I spent my first year as a CEO."
- The Body (The Pivot and the Struggle): The narrative transitions from the visceral physical action to the business parallel. Crucially, the AI must be instructed to explore the specific operational struggle, failure, or negative sentiment before pivoting to the lesson, thus capturing the 1.34x virality multiplier associated with negative/mixed sentiment. The body must be constrained to 150–200 total words, utilizing 3 to 4 short paragraphs with ample line breaks to create whitespace. It should translate complex business concepts into simple, highly relatable analogies. Emojis must be severely restricted (maximum one) to maintain authoritative gravity.
- The CTA (The Experiential Inquiry): The conclusion abandons generic engagement prompts in favor of a specific question that invites the audience to share a related narrative struggle.
- Example Execution: "What is the most persistent 'mushroom' you have had to kick out of your operational pipeline?"
3.2 Style Blueprint 2: The Contrarian Teardown (X vs. Y)
When the audio transcript detects high levels of founder frustration regarding industry norms, competitor practices, or pervasive myths, the agent routes the data to the Contrarian Teardown template. This style leverages the profound psychological power of debunking consensus and simplifying complex choices through stark, aggressive juxtaposition.
- The Hook (The Counter-Intuitive Claim): Directly and aggressively challenges conventional industry wisdom to force cognitive dissonance and halt the scrolling behavior.
- Example Execution: "Hiring the most qualified enterprise engineer was the most expensive mistake this startup ever made."
- The Body (The False Paradigm vs. The Reality): Clearly delineates the "old way" (X) versus the "new way" (Y). This blueprint relies heavily on bullet points and short sentences to rapidly reduce cognitive load and facilitate side-by-side comparison. To defend against accusations of "AI slop," the argument must be grounded in specific, concrete evidence or proprietary data unique to the founder's experience. It explicitly states the benefits of the new approach and the devastating costs of the old.
- The CTA (The Pivot to Action): Asks the audience to evaluate their own adherence to the broken paradigm.
- Example Execution: "Where is your team still optimizing for X when the market has already clearly shifted to Y?"
3.3 Style Blueprint 3: The Framework Breakdown (The Listicle/Carousel)
When the transcript contains a structured thought process, a multi-step solution, a strategic update, or an actionable tutorial, the agent selects the Framework Breakdown. This blueprint is the designated candidate for automatic conversion into the highly favored Document Carousel format.
- The Hook (The Promise of Value): Creates an immediate information gap and promises a highly actionable, structured solution grounded in recent success.
- Example Execution: "We cut our cloud computing overhead by 40% in three weeks. Here is the exact 4-step framework my team deployed."
- The Body (The Architecture of Steps): The content is chunked into logical, discrete, and easily digestible steps. If rendered as a text post, it utilizes numbered lists and specific formatting cues (e.g., bullet points with arrows '→') for optimal visual flow. The tone shifts from vulnerable to highly authoritative, instructional, and objective.
- The CTA (The Implementation Check): Focuses heavily on practical application and immediate value realization.
- Example Execution: "Which of these four operational steps represents the biggest bottleneck in your current infrastructure?"
3.4 Style Blueprint 4: The Innovation Journey and Success Narrative
When the founder records audio regarding a major company win, a product launch, or overcoming a massive operational hurdle, the agent employs the Success Narrative.
- The Hook (The Transformation): Focuses on the delta between the past state and the current state, highlighting the magnitude of the achievement.
- The Body (The Concrete Evidence): Details the journey of innovation, providing concrete evidence of the product's value and the relentless pursuit of excellence required to achieve it. It avoids vague benefit claims, instead using specific numbers, data points, and real-world results to build credibility.
- The CTA (The Future Outlook): Invites discussion on the implications of the innovation for the broader industry.
4. Supermemory Integration: State and Context Management Rules
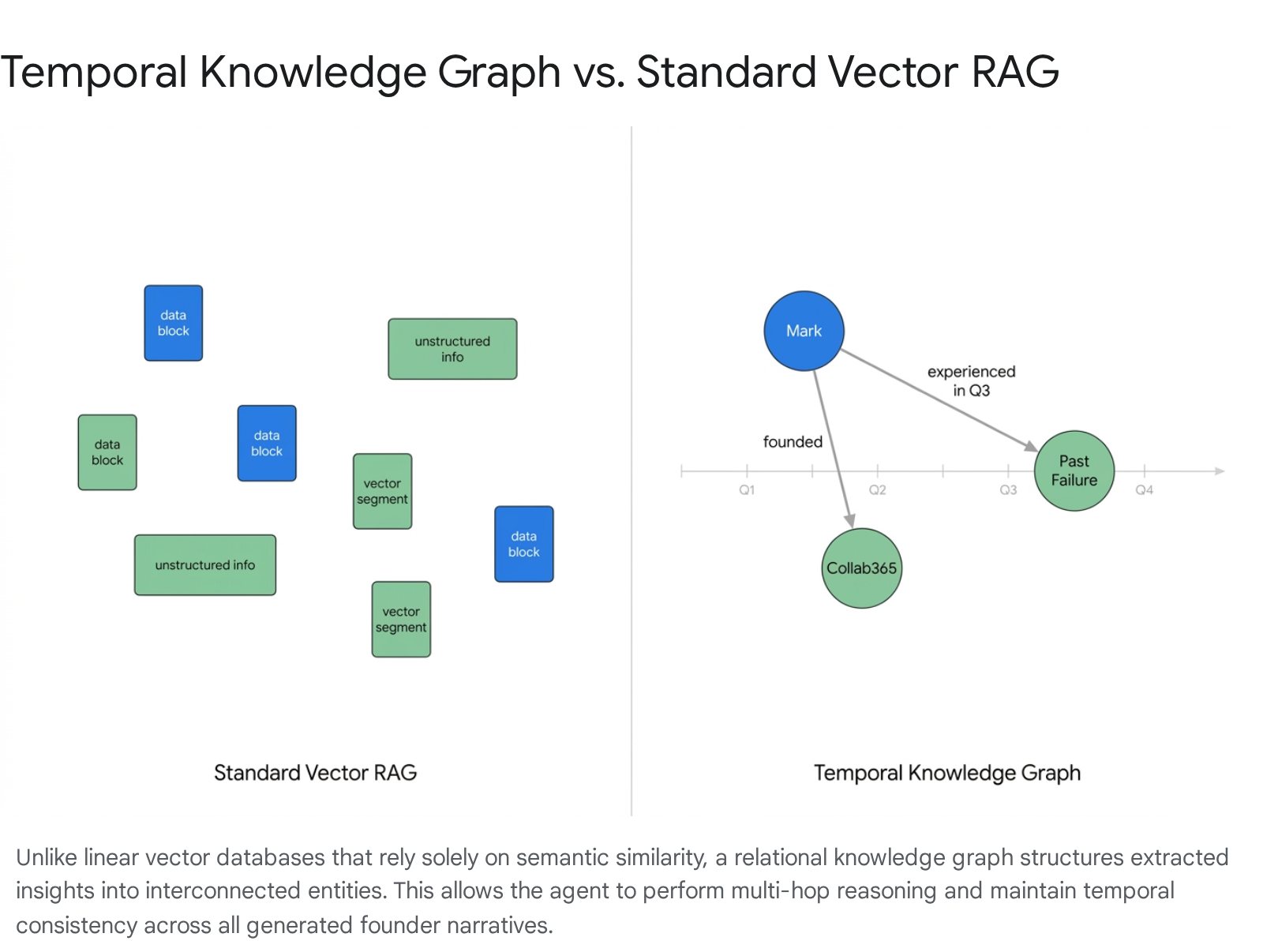
The defining architectural characteristic that elevates this system from a basic summarization script to an autonomous "Ghostwriter" is its sophisticated memory infrastructure. Standard Retrieval-Augmented Generation (RAG) models rely on flat vector databases that excel at finding semantically similar text chunks. However, vector search is fundamentally stateless, unversioned, and lacks temporal understanding; it cannot organically trace a chain of reasoning, enforce complex business logic, or understand why two pieces of information connect across time. For example, a vector database might retrieve an old quote from the founder praising a specific software tool, entirely missing a recent update where the founder abandoned that tool due to critical failures.
To achieve true context personalization and strategic consistency over months and years, the AI agent must interact with a "Supermemory" modeled as a Temporal Knowledge Graph seamlessly integrated with hybrid vector search capabilities. This allows the agent to build a continuous, evolving profile of the founder's beliefs, past experiences, interpersonal network, and company milestones.
4.1 The Write Protocol: Extraction and Archival Rules
The generative agent must not blindly dump entire, unedited transcripts into the Supermemory database. Doing so rapidly dilutes the signal-to-noise ratio, rendering retrieval highly inefficient. The Write Protocol must execute exclusively at the conclusion of every successful post-generation cycle, distilling the interaction into structured memory.
- Factual Assertion Extraction: A dedicated extraction sub-agent parses the cleaned transcript to identify hard facts, project updates, financial metrics, and chronological observations (e.g., "Churn dropped to 2% this month," or "We hired a new CTO in Q3"). These assertions are written as distinct new nodes and edges within the knowledge graph.
- Belief State and Point of View (POV) Mapping: The extraction agent identifies philosophical stances, contrarian opinions, or unique points of view expressed by the founder. These are stored as persistent persona traits, ensuring that future outputs never adopt a stance contrary to the founder's established worldview.
- Temporal Tagging and Conflict Resolution: If a newly ingested fact contradicts an older fact (e.g., "We are completely pivoting away from Product X"), the Supermemory does not destructively overwrite the old data. Instead, it applies a strict temporal stamp to the new insight, updating the graph to reflect that the preference or strategy has evolved, thereby maintaining a historical record of the founder's decision-making process.
- Narrative Metaphor Indexing: The specific "mundane metaphors" utilized (e.g., the mushroom anecdote, the broken coffee machine) are highly vectorized and stored. This indexing ensures the generative agent possesses a perfect ledger of past creative choices, guaranteeing it never accidentally recycles the exact same metaphor in future posts, preserving the illusion of spontaneous human thought.
4.2 The Read Protocol: Contextual Injection Rules
When a new raw audio transcript is received via email, the agent does not immediately begin drafting text. It must first query the Supermemory using a structured Read Protocol to achieve what is termed "context personalization".40
- Entity Resolution and Semantic Expansion: The agent analyzes the raw transcript to identify core entities (e.g., "employee retention," "Q3 deadline"). It queries the graph for all past assertions, historical company facts, and previous public quotes related to these specific entities.
- Multi-Hop Relational Augmentation: The true power of the graph emerges here. If the founder is discussing a recent operational success, the agent queries the memory for a past failure or historical bottleneck relationally linked to the same project. This contextual injection allows the drafting agent to autonomously construct a highly compelling "struggle-to-triumph" narrative arc without requiring the founder to explicitly recall or mention the past failure in their morning audio recording.
- Voice DNA Calibration Loading: The agent retrieves the static JSON-LD Voice DNA profile, integrating the founder's precise hex colors for visuals, specific tone markers, formatting rules, and the strict "Never Say" list to calibrate the operational parameters of the drafting LLM before a single word is generated.
5. The Step-by-Step Multi-Agent Execution Pipeline
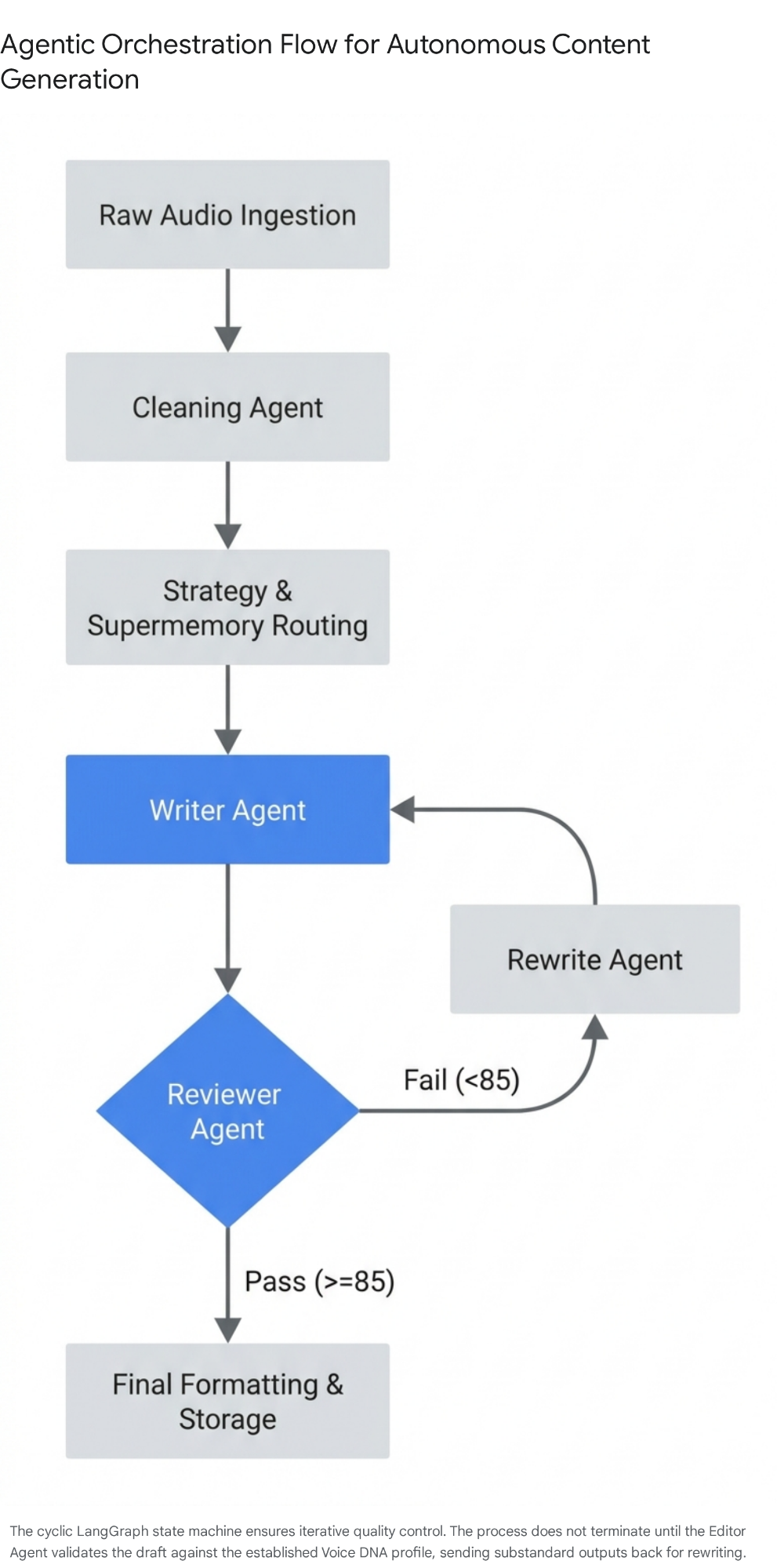
To reliably and securely transform unstructured, stream-of-consciousness audio into high-converting, platform-ready content, the system must utilize a cyclical, stateful multi-agent architecture (such as LangGraph or Autogenesis). A single-prompt approach inevitably degrades into generic output; multi-agent systems succeed because they organically replicate the iterative, multi-stage cognitive processes of a professional human writer—drafting, critiquing, reviewing, and revising.
The entire operational pipeline revolves around a shared data structure, commonly defined as an AgentState object (a typed dictionary), which persists, evolves, and carries context across the various specialized agentic nodes.
Pipeline Stage 1: Ingestion and the Cleaning Agent
- Input Trigger: The system receives the raw audio file via a designated email pipeline and processes it through a high-fidelity, advanced transcription API (e.g., OpenAI's Whisper) to generate a raw text payload.
- Processing Action: The raw text is highly unstructured, containing natural stumbles, tangential thoughts, and filler words. The Cleaning Agent processes the text to strip noise, normalize the data, and distinctly separate the "mundane physical observations" (the environmental color of the walk) from the core "business logic" (the update or frustration).
- State Output: A structured, clean context summary is appended to the AgentState.
Pipeline Stage 2: Semantic Routing and Knowledge Retrieval
- Processing Action: The Strategy Agent (acting as a supervisor node) analyzes the cleaned context to determine the primary intent. Based on semantic markers and emotional detection (e.g., detecting high frustration), it routes the data to one of the predefined structural templates in the Style Matrix (e.g., selecting the Contrarian Teardown).
- Retrieval Action: Simultaneously, the system executes the Supermemory Read Protocol. It queries the Temporal Knowledge Graph, retrieving historical facts, relationally linked past narratives, and the precise JSON-LD Voice DNA.
- State Output: The selected Template ID, the structural blueprint, and the retrieved grounding data are locked into the AgentState to prevent hallucinations and enforce factual accuracy.
Pipeline Stage 3: Draft Generation (The Writer Agent)
- Processing Action: The specialized Writer Agent receives the fully populated AgentState. It utilizes the CRISP framework (Context, Role, Instruction, Structure, Parameters) to tightly constrain the LLM's generative capacity. It strictly adheres to the selected blueprint's structural rules, ensuring the hook is compelling (dual-line constraint) and the Call-to-Conversation is appropriately experiential. It weaves the "mundane metaphor" retrieved from the cleaning phase into the business logic.
- State Output: Draft Version 1.0 is generated and stored.
Pipeline Stage 4: The Review Node (The Quality & Emotion Agent)
- Processing Action: This is the critical quality control layer that prevents the publication of slop. The Reviewer Agent acts as a hostile, independent editor. It evaluates Draft 1.0 against strict, weighted criteria:
- Authenticity and Voice Match (40%): Does the text genuinely sound like the founder, or does it sound like a machine? Does it successfully avoid all forbidden corporate jargon specified in the Voice DNA? 43
- Factual Accuracy and Grounding (30%): Does it align perfectly with the Supermemory assertions, or did the LLM hallucinate a metric? 43
- Formatting and Platform Compliance (30%): Does it strictly respect the line break constraints, the emoji limits, and the exact hook structure required for LinkedIn virality? 4
- Logic Gate: The Reviewer Agent generates a numerical score out of 100.7 If the score falls below a strict predefined threshold (e.g., 85/100), the draft is rejected and routed to the Rewrite Agent along with specific critique notes detailing exactly why the draft failed. This autonomous cycle repeats until the threshold is met or a maximum iteration limit (e.g., 3 rounds) is reached, at which point human intervention is requested.
Pipeline Stage 5: Final Formatting and Execution
- Processing Action: Once a draft successfully clears the Review Node, the Style Agent applies the final platform-specific formatting parameters. It attaches any extracted raw images or, if the Document Carousel template was selected, triggers an external script to dynamically generate the PDF file adhering to the strict design specifications.
- State Output: The finalized asset is stored in a clean JSON/YAML store, delivered to a human-approval dashboard (e.g., via Slack integration), or pushed directly to a LinkedIn scheduling API. Simultaneously, the Supermemory Write Protocol is triggered to archive the new insights and lock the metadata into the knowledge graph.
6. The Continuous Improvement Loop: Self-Evolving Autonomous Systems
An enterprise-grade autonomous content engine must not remain static; it must possess the capability to learn dynamically from its interactions with the market. Implementing a robust continuous feedback loop ensures that the agentic system becomes increasingly sophisticated over time, adapting to shifting algorithmic priorities, evolving audience preferences, and platform modifications. This requires moving the architecture toward advanced concepts seen in Autogenesis frameworks, where specialized agents negotiate and evolve their own operational protocols and workflows based on empirical performance data rather than just executing rigid, human-specified logic.
6.1 Automated Telemetry and Metric Ingestion
To facilitate self-evolution, the system requires a scheduled webhook integration (e.g., utilizing tools like Apify or the native LinkedIn API) to autonomously pull detailed performance telemetry 72 hours post-publication. The agent must evaluate specific, high-signal metrics far beyond mere vanity numbers (likes):
- Impression-to-Comment Ratio: This explicitly measures the psychological effectiveness of the Call-to-Conversation (CTC) and the true resonance of the narrative hook.
- Dwell Time Proxies: For carousel formats, tracking the completion rate or proxy engagement metrics to assess narrative retention and slide drop-off rates.
- Semantic Sentiment Analysis: Parsing the actual text of the user comments to determine if the post sparked genuine, high-value experiential discussion or simply generic agreement.
6.2 The Viral Post-Mortem: Modifying the JSON-LD Voice DNA
When the telemetry indicates that a post has "gone viral" (defined operationally as exceeding historical engagement baselines by a statistically significant margin), the system engages a specialized Diagnostic Agent.
- Linguistic Extraction: The Diagnostic Agent performs a granular analysis of the viral post to identify which specific syntactic structures, unique vocabulary choices, or exact metaphor typologies resonated most effectively with the audience.
- Schema Evolution: It then programmatically updates the JSON-LD Voice DNA schema to increase the mathematical weighting of those specific linguistic elements in future generation prompts, essentially "teaching" the Writer Agent what specific tones or structures yield the highest ROI.
- Reinforcement Learning via Algorithmic Reweighting: If longitudinal data reveals that the "Contrarian Teardown" style consistently yields a 20% higher engagement rate than the "Framework Breakdown" style, the system autonomously adjusts the probability matrix within the Strategy Agent. In future ambiguous semantic routing scenarios where a transcript could logically fit multiple templates, the system will mathematically default to the historically superior blueprint.
6.3 The Failure Post-Mortem: Updating Negative Constraints
Conversely, when a post underperforms or "bombs," the Diagnostic Agent conducts a rigorous root-cause analysis. It asks specific diagnostic questions: Did the hook fail to contain sufficient tension? Was the corporate jargon threshold accidentally breached by the LLM? Did the post utilize a purely positive sentiment, thereby failing to trigger the psychological authenticity multiplier? 4
Once the system identifies the probable failure point, it updates its "Negative Constraints" parameters. It adds specific phrases, structural approaches, or weak CTA formulations to a localized, dynamic "Do Not Use" list (the 'Never Say' parameter) within the Supermemory context window. This effectively inoculates the Writer Agent, ensuring it avoids repeating the specific creative decisions that led to algorithmic suppression, guaranteeing that the system's output quality compoundingly improves with every cycle.