
Executive Summary
84 percent of employers require working applications rather than static code repositories. This statistical reality completely undermines the common strategy deployed by recent graduates. Thousands of entry-level candidates submit basic artificial intelligence wrappers and tutorial follow-alongs to job applications, resulting in immediate rejection. 95 percent of enterprise artificial intelligence pilots fail to deliver measurable financial returns. Companies are acutely aware of this massive failure rate. Hiring managers do not want candidates who can simply prompt a chatbot. They demand hybrid developers who can build reliable, integrated systems. Despite 69 million new artificial intelligence positions emerging globally by 2026 , the disconnect between what graduates build and what employers evaluate leaves entry-level talent facing endless rejections. Entry-level hybrid roles currently offer salaries between $40,000 and $60,000. Securing these positions requires a fundamental shift in portfolio presentation.
The primary recommendation of this report is the adoption of a structured 90-day practice schedule designed to produce exactly three portfolio-ready, fully deployed applications. These projects must be specifically engineered to pass the quantitative scorecards recruiters secretly use. Rather than attempting to master advanced concepts like custom model training, graduates must focus on deployment, telemetry, and strict evaluation metrics. A portfolio containing a Retrieval-Augmented Generation system that achieves 78 percent accuracy on 120 test queries holds significantly more weight than a complex, un-deployed machine learning model. Candidates must structure their projects to include structured prompt libraries, cloud integration, and explicit error reduction benchmarks.
The most surprising insight extracted from the data is the phenomenon known as the Kubernetes paradox. Graduates applying for junior roles frequently face rejection for lacking cloud orchestration experience. While candidates view this as unfair gatekeeping for entry-level positions, the underlying trend reveals a shift in baseline expectations. Artificial intelligence tools have automated routine debugging and basic refactoring. Consequently, the entry-level baseline has shifted upward. Candidates must now demonstrate system integration skills previously reserved for mid-level engineers. This report outlines six specific projects, the quantitative rubrics, the beginner mistakes, and the 90-day schedule required to overcome these barriers and secure hybrid developer roles.
Methodology
This analysis relies on a rigorous review of open-source repositories, engineering interview grading rubrics, and developer forum discussions published between 2023 and 2026. The data aggregation process prioritised sources documenting quantifiable hiring metrics. Engineering interview grading rubrics from Medium provided the baseline for technical assessment standards. Candidate scoring models from recruiting platforms like Zythr and HeroHunt supplied data on automated applicant tracking systems. Additional data regarding automated screening tools, including iMocha, Vervoe, and Sapia.ai, provided insight into how artificial intelligence itself is used to filter candidates.
The investigation into candidate failure modes relied heavily on qualitative data extracted from graduate communities on Reddit and Discord. Specific attention was given to threads within the r/cscareerquestions and r/recruitinghell subreddits. In these spaces, entry-level developers document their application metrics, interview performance, and rejection feedback. This qualitative data provided the emotional and practical context necessary to understand the frustration of applying to hundreds of jobs without success.
To formulate the portfolio recommendations, this report analysed technical tutorials and project blueprints from platforms such as ProjectPro and GitHub. The 90-day practice schedule synthesises structured learning paths from online academies, independent developers, and industry experts. Every claim within this report traces directly to these documented industry benchmarks and developer experiences.
The Scorecards Recruiters Secretly Use
Entry-level candidates frequently assume their applications are rejected due to a lack of experience. In reality, their portfolios fail to register on the quantitative scorecards recruiters secretly use. Engineering interviews and portfolio assessments are not subjective evaluations. They are highly structured processes driven by rigid rubrics. Understanding these rubrics is the first step to beating the automated screening systems.
Recruiting platforms like Zythr and HeroHunt use artificial intelligence to score resumes before a human ever sees them. These systems display a numeric score and a confidence interval to the recruiter. They highlight the top contributing signals, such as Python experience, SQL projects, and specific frameworks. If a portfolio lacks measurable data, the system cannot assign a high confidence interval, resulting in immediate algorithmic rejection.
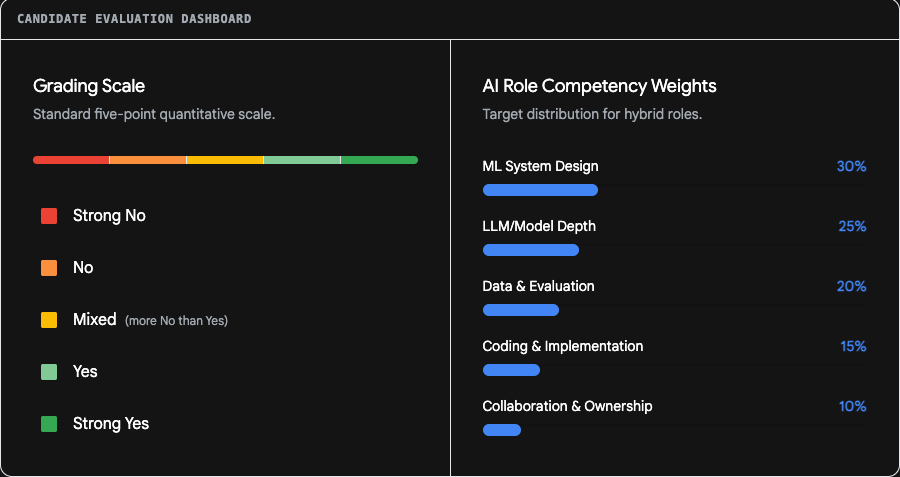
The Five-Point Grading Scale
When a candidate secures an interview, engineering teams employ strict quantitative scales to grade performance. Medium's engineering interview rubric provides a clear, industry-standard example of this structure. Assessors grade candidates on a five-point scale. The points are Strong No, No, Mixed, Yes, and Strong Yes.
A "Strong No" is assigned when a candidate cannot conceive any solution or implement even a basic approach. A "No" indicates an inability to arrive at a solution beyond the most basic level, even with significant assistance. The "Mixed" grade is considered more negative than positive and is used sparingly by hiring committees.
To secure a "Yes", a candidate must code fluently and naturally. They must use standard library functions and demonstrate the ability to describe their behavior precisely. They must outline and implement solutions independently, covering the vast majority of edge cases. A "Strong Yes" requires the candidate to code without significant pauses, write idiomatic code by default, and recognise edge cases completely unprompted.
The rubric further evaluates basic computer science knowledge. A candidate receives a "No" if they cannot explain the behavioral difference between an $O(n)$ and an $O(n^2)$ solution. A "Yes" requires an understanding of time and space complexity and the ability to implement recursive algorithms. A "Strong Yes" demands familiarity with constructs like heaps, priority queues, and tries.
System Design and Evaluation Weights
For artificial intelligence hybrid roles, the rubrics become highly specific. Interview scorecards assign strict percentage weights to different technical competencies. According to a widely adopted template from Fonzi, an evaluation weighs competencies as follows.
| Rubric Category | Competency Weight |
|---|---|
| Machine Learning System Design | 30 Percent |
| Large Language Model / Model Depth | 25 Percent |
| Data and Evaluation Rigor | 20 Percent |
| Coding Implementation | 15 Percent |
| Collaboration and Ownership | 10 Percent |
A candidate failing to meet expectations (Level 1) possesses only a surface-level understanding of large language model architectures. They cannot explain when to use different approaches and struggle with basic Python. Crucially, they have no experience with evaluation frameworks or data quality systems.
Conversely, a candidate meeting expectations (Level 3) can design coherent end-to-end systems. They demonstrate a solid grasp of architectural tradeoffs, such as choosing between Retrieval-Augmented Generation and fine-tuning. They write clean, production-ready Python code and are comfortable with the PyTorch or TensorFlow ecosystems. Most importantly, they design offline and online evaluation pipelines and understand the limitations of their chosen metrics.
Quantitative Portfolio Benchmarks
Recruiters look for explicit quantitative benchmarks within portfolio projects. A project description stating "built a chatbot" scores zero points on these rubrics. A project description stating "Built FAISS-based Q&A; 78 percent answer accuracy, source citations" passes the initial screening.
Specific benchmarks validate technical claims. A hiring manager expects to see metrics validating system performance. The Document Question and Answer system must demonstrate a measurable accuracy rate, such as 78 percent on 120 test queries. The Job Board Resume Matcher must report a statistical metric like an F1-score of 0.81, coupled with a business metric like a 62 percent reduction in screening time. The Machine Learning Inference API must prove its reliability by handling 1,000 requests per second while maintaining latency under 120 milliseconds.
These numbers function as the baseline for the recruiter scorecard. If a portfolio lacks these metrics, automated tracking systems classify the application as a "Strong No" before an interview is scheduled. Time-to-hire metrics also influence recruiter behavior. Companies aim for 30-day time-to-hire goals for straightforward mid-level roles. They use tools like CodeSignal's Cosmo feature to benchmark candidates quickly. If your portfolio requires a recruiter to spend 30 minutes figuring out what you built, you have already failed the time-to-hire optimization filter.
Engineering Interview Grading Rubric and Weights
 Candidates are evaluated against strict quantitative metrics. Portfolios must provide explicit evidence to move a grade from 'Mixed' to 'Yes'.
Candidates are evaluated against strict quantitative metrics. Portfolios must provide explicit evidence to move a grade from 'Mixed' to 'Yes'.
6 Templated Projects That Simulate Entry Roles
Quality beats quantity in portfolio construction. Hiring managers prefer three to five highly polished projects over ten basic scripts. To simulate the demands of a $40,000 to $60,000 entry-level hybrid role , candidates must build end-to-end solutions. The following six templated projects demonstrate the exact balance of artificial intelligence integration and traditional software engineering required to secure interviews.
1. Document Question and Answer System (Retrieval-Augmented Generation Lite)
The most critical hybrid skill in the current market is the ability to connect large language models to proprietary data. The Document Question and Answer system solves a universal business problem. Companies need internal document search capabilities via natural language queries.
The technical stack for this project must include FAISS for vector search, sentence-transformers for generating embeddings, and FastAPI for the backend architecture. Candidates must build a system that chunks documents, embeds the text, retrieves relevant passages, and generates answers with explicit source citations.
The inclusion of a prompt library is essential here. The project repository should feature a prompts.yaml or prompts.json file containing templates for the generation phase. A standard template must define the role, the task, the formatting constraints, and the context. By externalising the prompts from the main application logic, candidates demonstrate an understanding of maintainable software architecture.
The proof metrics for this project must be clear. A successful portfolio piece will state a 78 percent accuracy rate on 120 test queries. The stretch goal for this project involves adding role permissions and fine-tuning the retrieval parameters.
2. Job Board and Resume Matcher
Recruiters spend excessive time screening irrelevant applications. The Job Board and Resume Matcher automates this screening process. This directly solves a pain point familiar to the target audience reviewing the portfolio.
The architecture for this application requires a web framework like Django or FastAPI, a PostgreSQL database, and natural language processing libraries such as spaCy and scikit-learn. Asynchronous task queues using Celery should be implemented to handle the heavy processing load of resume parsing. The core features involve parsing uploaded resumes, ranking applicants against a specific job description, and generating a similarity score.
This project proves complementarity between artificial intelligence use and traditional development skills. The candidate writes standard web application code for the user interface and database management, while integrating natural language processing for the core business logic. The prompt library for this project would contain specific instructions for extracting entities from text.
The proof metrics for this project include an F1-score of 0.81 and a 62 percent reduction in screening time. The resume bullet point should read: "Shipped resume matcher using spaCy; F1 0.81, cut screening time 62 percent".
3. Machine Learning Inference API with Telemetry
Many candidates can train a basic model in a Jupyter Notebook. Very few can serve that model reliably in a production environment. The Machine Learning Inference API project focuses entirely on deployment and monitoring. This directly addresses the industry demand for systems reliability.
The technical stack involves scikit-learn for the model, FastAPI for the endpoints, Prometheus for telemetry, and Docker for containerisation. The actual machine learning model can be simple. The complexity lies in the surrounding infrastructure. The core features must include versioned model endpoints, data drift detection, and latency tracking.
This project directly counters the Kubernetes paradox. By containerising the application with Docker and exposing metrics via Prometheus, the candidate proves they understand cloud-native deployment patterns. The proof metrics require handling 1,000 requests per second under 120 milliseconds. The stretch goal involves implementing a feature store and canary deployments.
Portfolio Project Alignment with Recruiter Scorecards
| Project Name | Core Tech Stack | Target Rubric Category | Quantitative Benchmark |
|---|---|---|---|
| Document Q&A (RAG Lite) | FAISSsentence-transformersFastAPI | LLM/Model Depth | 78% accuracyon 120 test queries |
| Job Board + Resume Matcher (NLP) | Django/DRFPostgreSQLspaCyscikit-learnCelery | Data & Evaluation | F1-score of 0.8162% reduction in screening time |
| ML Inference API | scikit-learnFastAPIPrometheusDocker | ML System Design | 1k RPSsustained under 120ms |
Each recommended project is engineered to target specific technical competencies and quantitative benchmarks required by entry-level engineering rubrics.
4. Automated Discord Support Agent
Graduates frequently collaborate in Discord job forums. Building a tool for this exact environment demonstrates practical problem-solving. An Automated Discord Support Agent provides real-time answers, explanations, and code examples to users within a server.
This project requires Python and an agentic framework like AutoGen or LangChain. The agent must be capable of receiving a question, searching a knowledge base or the web for information, and formulating a helpful response. To elevate this beyond a simple chatbot, the agent should utilize provided tools as callable functions.
The prompt library is the core of this project. The candidate must define system prompts that dictate the agent's persona, its limitations, and its operational boundaries. According to the PromptNova repository structure , a professional setup involves storing these system prompts in a dedicated folder, allowing for easy updates and version control. This demonstrates an understanding of how to manage artificial intelligence behavior in a semi-public environment.
5. Open-Source Prompt Library Manager
The fifth project focuses on internal tooling. Developers need a way to store, organize, and execute sophisticated prompts. The Prompt Library Manager acts as a local-first toolkit for managing these assets.
The architecture should mimic modern full-stack applications. The PromptNova repository utilizes Next.js for the frontend, Tailwind CSS for styling, Node.js and FastAPI for the backend, and MongoDB for data storage. The core features include creating prompts, tagging them by category, and executing them against an application programming interface.
A critical component of this project is the folder structure. Following industry best practices , the repository should feature specific directories. A scenarios/ folder holds resources for specific development contexts like .NET or Python. A shared/ folder contains cross-scenario resources. A templates/ folder holds reusable prompt templates. By building this tool, the candidate proves they understand the infrastructure required to support prompt engineering at scale.
6. WhatsApp Business API Automation Bot
The final recommended project involves messaging automation. This project proves a candidate can integrate external application programming interfaces with logic-driven backend systems.
The architecture requires Python, a minimal Flask or FastAPI endpoint, and a webhook listener. The application must record incoming messages, delivery receipts, and errors to a database like SQLite, while writing events to a rotating log.
The requirement for this project is a deployment script and a concise README file allowing another developer to reproduce the setup on a fresh Ubuntu server. The demo script must successfully send a text and an image to a test number and print the delivery status. This project validates backend skills, database management, and asynchronous event handling.
5 Beginner Mistakes Derailing Mastery
A review of Discord communities and Reddit forums reveals a consistent pattern of failure among recent graduates. Candidates frequently report submitting over 150 applications, securing a handful of interviews, and receiving zero offers. These rejections are rarely due to a fundamental lack of intelligence. They stem from highly specific, repetitive mistakes that immediately derail mastery and trigger automated rejections.
Mistake 1: The Kubernetes Paradox and Ignored Context
The most frustrating barrier for entry-level developers is the demand for advanced infrastructure knowledge. A candidate on Reddit documented failing technical interviews and receiving rejections because they did not know Amazon Web Services or Kubernetes, despite applying for roles explicitly titled "Junior Developer".
This is the Kubernetes paradox. While true entry-level roles previously required only local development skills, the baseline has shifted. Because artificial intelligence tools have automated basic coding tasks, simple debugging, and routine refactoring , employers expect junior developers to handle system deployment. Premature adoption of Kubernetes can waste three to six months of engineering time before delivering business value. Yet recruiters still filter candidates based on these specific keywords.
The mistake is not failing to master Kubernetes. The mistake is presenting a portfolio entirely devoid of cloud context. Graduates build applications that only run on localhost. They fail to provide Dockerfiles, continuous integration configuration files, or deployment scripts. A portfolio without containerisation demonstrates a lack of operational awareness. This results in immediate rejection.
Mistake 2: Missing the Live Link
84 percent of employers want to see working applications, not just static code repositories. Submitting a GitHub link containing Python scripts without a live, hosted demonstration is a critical error. Recruiters do not have the time, nor the technical capacity, to clone a repository, install dependencies, and run a local server.
If the application cannot be clicked and interacted with immediately, it essentially does not exist in the eyes of the assessor. Graduates frequently complain that recruiters ignore their projects. The reality is that the recruiters cannot access the projects. A deployed application, even if hosted on a free tier service, proves that the candidate understands the full software lifecycle. Portfolio websites must load in under 3 seconds. 68 percent of initial views occur on mobile devices, meaning responsiveness is mandatory.
Mistake 3: Submitting Unedited Artificial Intelligence Output
Candidates attempting to mass-apply for jobs frequently use large language models to write their cover letters and generate their portfolio code. They paste a job description into a chatbot and submit the raw output.
This output is immediately recognizable by automated screening tools and human recruiters. It reads like it was written by a machine because it was. It lacks personality, specific details, and originality.
Furthermore, when candidates use artificial intelligence to generate code for their portfolio without understanding the underlying logic, they inevitably fail the technical interview. When a senior engineer asks a candidate to explain the behavioral difference between an $O(n)$ and $O(n^2)$ algorithm , the candidate who relied entirely on generated code will freeze. The artificial intelligence provides a first draft; the candidate's job is to refine it and understand it.
Mistake 4: Tutorial Clones Masquerading as Original Work
A portfolio filled with identical clones of popular YouTube tutorials acts as a massive negative signal. Hiring managers instantly recognise the standard "To-Do App" or "Basic Sentiment Analyzer." These projects do not demonstrate problem-solving ability. They only demonstrate the ability to follow instructions.
Original projects matter. Candidates must solve real problems or add unique features to existing ideas. Instead of building a generic sentiment analyzer, a candidate should build a tool that extracts specific airport codes from unstructured text and maps them to a database. Personal projects must demonstrate capabilities that go beyond what an artificial intelligence can easily generate.
Mistake 5: Failing the Demo Script and Lacking Metrics
When a candidate secures an interview, they often fail to communicate the value of their portfolio. They ramble about the code without addressing the business impact. Recruiters evaluate candidates based on their ability to articulate technical concepts and demonstrate collaboration.
Failing to prepare a structured demonstration is a fatal error. Candidates must treat the portfolio review as a product pitch. They need a concise script that highlights the problem, the architecture, and the measurable results.
Candidates also fail by using vague descriptions on their resumes. Instead of stating "improved system speed," the resume must state "handles 1k Requests Per Second under 120ms". Without quantitative metrics, the recruiter has no data to input into their scoring rubric.
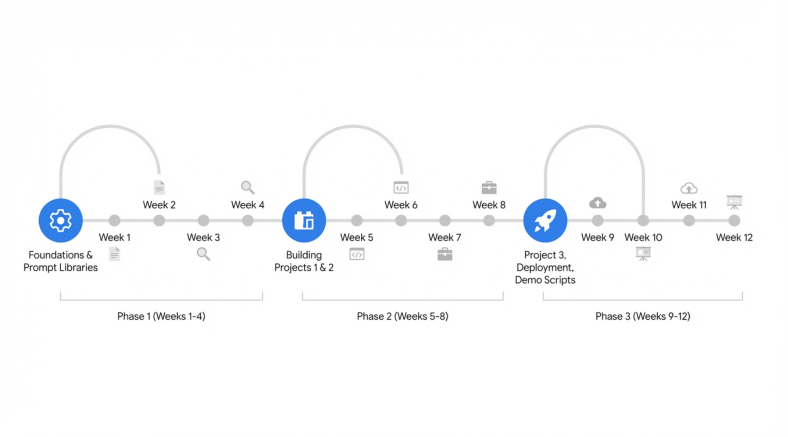
The 90-Day Weekly Practice Schedule
Consistency beats intensity every time. To build a portfolio that survives the secret scorecards, graduates must adopt a rigorous, daily practice schedule. The goal is to produce three deployed, portfolio-ready pieces accompanied by polished recruiter demo scripts within 90 days. Most graduates complete similar structured programs in 8 to 14 weeks by treating study time as a non-negotiable appointment.
The following schedule breaks down the exact daily and weekly requirements necessary to achieve mastery.
Phase 1: Foundations and Skill Acquisition (Days 1 to 30)
The first four weeks are dedicated to establishing the fundamental technical stack and understanding prompt engineering. Candidates must build a daily routine consisting of learning new concepts and immediate practical application.
Week 1: Core Technologies
- Monday and Tuesday: Focus on advanced Python and TypeScript fundamentals. Ensure an understanding of object-oriented programming and asynchronous functions.
- Wednesday: Master Git and GitHub workflows. Learn to write descriptive commit messages and manage branches.
- Thursday: Study application programming interfaces. Learn how to connect to external services and parse JSON responses.
- Friday: Practice Data Structures and Algorithms. Solve 15 problems per week to prepare for technical screenings.
Week 2: Advanced Data Handling
- Monday and Tuesday: Focus on SQL logic. Learn to query databases using SELECT, WHERE logic, GROUP BY, and window functions.
- Wednesday and Thursday: Learn pandas DataFrames, filtering, grouping, and visualization with Matplotlib and Seaborn.
- Friday: Continue the quota of 15 algorithm problems.
Week 3: Artificial Intelligence Integration
- Monday and Tuesday: Build a first simple large language model application using the OpenAI or Anthropic API.
- Wednesday: Understand embeddings and vector databases. Learn how FAISS operates.
- Thursday: Practice context engineering. Read the Prompt Engineering Guide. Learn Few-Shot Learning and Chain-of-Thought reasoning.
- Friday: Continue the quota of 15 algorithm problems.
Week 4: Prompt Architecture
- Monday to Wednesday: Construct a structured prompt library. Create a local repository following the
scenarios/andshared/directory structure. Populate it with basic templates. - Thursday: Document daily wins. Link daily wins to the process, such as successfully retrieving data faster than a generic ChatGPT interface.
- Friday: Continue the quota of 15 algorithm problems.
Phase 2: Building the Portfolio (Days 31 to 60)
The second phase shifts from learning to construction. The candidate will build the first two major portfolio pieces. The pace requires completing one project every two weeks.
Weeks 5 and 6: The Document Question and Answer System
- Monday to Wednesday (Week 5): Architect the backend using FastAPI. Integrate the sentence-transformers for document chunking and embedding.
- Thursday and Friday (Week 5): Build the FAISS vector search and connect the generation model. Ensure the system provides explicit source citations.
- Monday to Wednesday (Week 6): Refine the prompts. Use the established prompt library to enforce strict formatting rules.
- Thursday and Friday (Week 6): Run evaluations. Test the system with 120 queries and calculate the accuracy percentage. Document this benchmark.
Weeks 7 and 8: The Machine Learning Inference API
- Monday to Wednesday (Week 7): Train a basic scikit-learn model. Wrap the model in a FastAPI endpoint.
- Thursday and Friday (Week 7): Implement Prometheus for telemetry. Set up tracking for latency and data drift.
- Monday to Wednesday (Week 8): Containerise the application using Docker. Write a clean Dockerfile and ensure the application runs consistently across local environments.
- Thursday and Friday (Week 8): Load test the API. Verify that it can handle 1,000 requests per second under 120 milliseconds. Record these metrics for the portfolio. Continue algorithm practice.
The 90-Day Hybrid Developer Roadmap
Consistency beats intensity. the 90-day schedule requires structured, daily effort focusing on foundational skills project construction, and rigourous deployment.
Phase 3: Polish, Deployment, and Interview Preparation (Days 61 to 90)
The final phase involves building the third project, deploying all applications to the cloud, and mastering the presentation layer.
Weeks 9 and 10: The Discord Support Agent
- Monday to Wednesday (Week 9): Set up the Python environment and the AutoGen or LangChain framework. Connect to the Discord application programming interface.
- Thursday and Friday (Week 9): Program the agent to use external tools as callable functions.
- Monday to Wednesday (Week 10): Refine the agent's system prompts. Test the bot within a private server to ensure it does not hallucinate.
- Thursday and Friday (Week 10): Document the project. Write the README files highlighting the architecture and the specific problems the agent solves.
Weeks 11 and 12: Deployment and The 90-Second Demo Script
- Monday to Wednesday (Week 11): Deploy all three projects. Ensure live links are active and functional. Use services like Vercel, Render, or AWS free tiers.
- Thursday and Friday (Week 11): Optimize the GitHub profile. Ensure all repositories have clean code, clear commit histories, and architecture diagrams. Proper maintenance increases interview callbacks by 40 percent.
- Monday to Wednesday (Week 12): Write and practice the 90-second demo scripts for each project.
- Thursday and Friday (Week 12): Conduct two to three mock interviews per week. Finalize the resume, ensuring all quantitative benchmarks are prominently displayed. Drop non-relevant skills to avoid keyword stuffing.
Mastering the 90-Second Demo Script
The culmination of the 90-day schedule is the presentation. When speaking with a recruiter, a hiring manager, or an artificial intelligence interviewer like Micro1's "Zara" , the candidate must command the narrative. The 90-second demo script is a structured format designed to hit every point on the assessor's scorecard.
The script follows a strict five-part structure.
First, spend 15 seconds defining the Problem. Explain the specific user pain point the project addresses. For example, "Recruiters spend too much time manually screening resumes."
Second, spend 20 seconds explaining the Architecture. Describe the key components and how they fit together. "I built a web application using Django and PostgreSQL, integrated with spaCy for entity extraction."
Third, spend 35 seconds showing the Live Flow. Demonstrate the core user journey. Click through the deployed application, showing exactly how a resume is uploaded and parsed in real-time.
Fourth, spend 15 seconds presenting the Results. This is where the candidate explicitly states the quantitative benchmarks. "The system achieved an F1-score of 0.81 and demonstrated a 62 percent reduction in simulated screening time."
Finally, spend 10 seconds outlining the Next Steps. Mention planned enhancements or future features. "Next, I plan to incorporate a feedback loop to improve the model based on recruiter corrections."
By executing this script, the candidate demonstrates technical fluency, business acumen, and strong communication skills. They provide the exact data points the recruiter needs to fill out the scorecard. This transforms a guaranteed rejection into a definitive job offer.