What's Changed Since This Session
The Microsoft Fabric ecosystem has evolved aggressively since the foundational sessions recorded in mid-2024. The platform has transitioned from a promising unified analytics suite into a mature, AI-driven enterprise platform.
The user interface, underlying compute engines, and governance frameworks have all seen massive architectural overhauls. The following table summarizes the most critical technical shifts impacting the core data engineering and reporting workflows.
| Technology / Concept | Status in March 2026 | What Replaced It (if applicable) |
|---|---|---|
| Workspace Navigation | Replaced | Task Flows and Parent-Child Hierarchies within the OneLake Catalog. |
| Power BI Default Semantic Models | Deprecated / Disconnected | Independent Semantic Models generated manually via the web modeling experience. |
| Dataflow Gen2 Execution Engine | Replaced | The Modern Evaluator (Generally Available), utilizing.NET 8 for optimized query execution. |
| Direct Lake Storage Limitations | Upgraded | Composite Models, allowing the seamless mixing of Direct Lake tables with traditional Import tables. |
| Fabric Notebook Security | Upgraded | Customer Managed Key (CMK) encryption support at rest using Azure Key Vault. |
| Semantic Link | Generally Available | A fully integrated library bridging PySpark/Python ecosystems directly with Power BI analytical models. |
| Data Connectivity in Notebooks | Upgraded | Fabric Connection inside Notebooks, supporting Service Principal, Workspace Identity, and Token authentication directly in the UI. |
How to Build This Today
You saw Jessica demonstrate several core data workflows, from initial ingestion to final report rendering. Today, the methodologies for executing these same tasks require entirely new configuration paths and architectural considerations.
This section breaks down exactly how a senior consultant builds these solutions in March 2026. Every scenario includes step-by-step guidance, leveraging modern AI integrations and enterprise best practices.
Scenario 1: Setting Up a Lakehouse for Structured and Unstructured Data
You saw Jessica demo a Lakehouse setup from a relatively flat workspace view. Today, the entire workspace organization has been overhauled with visual project mapping.
The architectural decision between deploying a Lakehouse versus a Data Warehouse remains the most critical early choice in any Fabric deployment. The Fabric Lakehouse is best utilized by data engineers and data scientists processing raw, semi-structured, or completely unstructured data files. It heavily relies on the Apache Spark compute engine to perform large-scale ETL (Extract, Transform, Load) transformations and machine learning model training.
Conversely, the Fabric Data Warehouse is tailored specifically for Business Intelligence (BI) developers. It serves analysts who require high-performance, strictly structured relational data models and robust T-SQL capabilities for standard reporting. Modern enterprise data strategy mandates a unified platform, and OneLake serves as the underlying logical storage layer for both of these artifacts.
In 2026, the user experience introduces Task Flows, a visual mapping canvas that organizes your workspace items into logical pipelines. The creation of a Lakehouse should no longer be an ad-hoc action, but rather executed within this structured environment to ensure team visibility.
Step-by-Step March 2026 Build Instructions:
- Navigate to the Fabric portal and select the Workspaces icon in the left navigation pane.
- Select + New workspace and provide an enterprise-compliant naming convention.
- Expand the Advanced section in the configuration pane. Select Fabric capacity to ensure the workspace is physically backed by an F-SKU.
- Select Apply to provision the new environment.
- In the new workspace, locate the blank Task Flow canvas permanently docked at the top of the screen.
- Open the Add task dropdown menu located on the canvas ribbon and select the Store data task type.
- Select the newly created task card on the canvas. In the task details side pane that slides out, select Create new item and choose Lakehouse.
- Provide a logical name and confirm the creation.
The platform now provisions the Lakehouse infrastructure. Behind the scenes, it automatically generates the associated SQL analytics endpoint artifact.
Navigate to the OneLake Catalog to view your assets. Observe the new Parent-Child Hierarchy feature introduced in early 2026. The Lakehouse appears as the parent item, with the SQL Analytics Endpoint nested cleanly beneath it in a collapsible tree view. This hierarchy simplifies object selection and prevents developers from querying the wrong endpoint.
Data loaded into the managed area of this Lakehouse must be rigorously optimized for downstream reporting. Fabric enforces the Delta Lake format, which wraps open-source Parquet files with a transactional metadata layer. This architecture provides strict ACID (Atomicity, Consistency, Isolation, Durability) compliance and powerful time-travel querying capabilities.
When writing data to the managed area, ensure workspace schemas are explicitly enabled if organizational grouping is required. The data must be saved as properly formatted Delta tables rather than raw CSV or Parquet files. This strict adherence to Delta Lake is a hard prerequisite for enabling high-speed Direct Lake mode later in the pipeline.
Architectural Divergence: Lakehouse vs Data Warehouse in Fabric
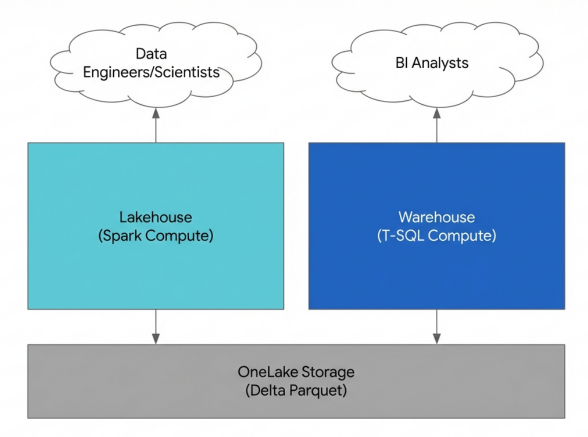
Both artifacts store data in OneLake using open Delta Parquet formats. The Lakehouse leverages Spark compute for versatile data engineering, while the Warehouse provides a dedicated SQL engine for structured analytics.
Quick Win: The Lakehouse Explorer Deep Link Collaboration is significantly streamlined in the 2026 UI. When troubleshooting a specific Delta table with a colleague, navigate to the Lakehouse Explorer. Select the ellipsis (...) next to the specific table and select Copy URL.This generates a unique deep link that opens the exact table preview in the grid view for the recipient, bypassing all standard workspace navigation.
For further granular details on administration and governance, consult the official Microsoft documentation: Navigate the Lakehouse Explorer.
Scenario 2: Multi-Language Data Exploration with Fabric Notebooks
You saw Jessica use Notebooks for basic multi-language data exploration as a superior alternative to Power Query. Today, Fabric Notebooks have evolved into highly secure, AI-augmented enterprise applications.
Notebooks still allow practitioners to seamlessly switch between Python, SQL, and Spark within a single interactive session. However, the 2026 update has aggressively enhanced the execution environment with zero-trust security controls. Workspaces can now enforce Customer Managed Key (CMK) encryption. This secures all notebook code and execution metadata at rest using organizational keys stored in Azure Key Vault.
Additionally, Microsoft introduced the ODBC Driver for Fabric Data Engineering in early 2026. This enterprise-grade connector delivers highly secure Spark SQL connectivity powered entirely through Fabric's internal Livy APIs.
Perhaps the most disruptive change is the General Availability of Semantic Link (specifically version 0.13.0 and above). This library establishes a native bridge between the data engineering persona and the Power BI analytical layer. Data scientists can now read calculated Power BI measures directly into Python pandas DataFrames, perform complex machine learning analysis, and write the optimized output back to OneLake.
Step-by-Step March 2026 Build Instructions:
- Navigate to your targeted workspace and locate the Task Flow canvas.
- Select Add task, choose Develop data, and assign the task to your project workflow.
- Select the task card, choose Create new item, and select Notebook.
- Alternatively, to import existing legacy code, bypass the task flow and select Import > Notebook > From this computer in the workspace view. Select the required
.ipynbfile and click Upload. - Once the notebook environment spins up, observe the Lakehouse Explorer pane on the left margin.
- If the notebook is disconnected, select Add Lakehouse and bind it to the specific Lakehouse created in Scenario 1.
- Configure the compute session. Select the default language dropdown in the top ribbon, which is typically set to PySpark.
- To utilize multi-language capabilities effectively, use "magic commands" at the absolute top of individual cells.
- Type
%%sqlto execute pure Spark SQL queries directly against the attached Delta tables.Type%%pysparkin the subsequent cell to instantly switch the context back to Python for complex dataframe manipulation. - Establish highly secure connections to external sources using the Fabric Connection inside Notebook pane.
- Select the Data tab on the ribbon, choose Connections, and configure a new link. The 2026 interface natively supports Workspace Identity Authentication, Basic Authentication, and Service Principal Authentication (SPN) directly within the UI UI. This completely eliminates the dangerous practice of hardcoding credentials in plain text.
- To execute modular code patterns, utilize the newly supported
%runmagic command. This allows you to execute auxiliary Python utility notebooks directly from the main execution thread without duplicating code.
The deep integration of Copilot and Fabric Data Agents completely transforms the manual coding workflow. The AI assistant pane permanently resides on the right side of the notebook interface, contextually aware of your attached Lakehouse schema.
Quick Win: Copilot Snippet Generation Do not waste time memorizing the complex syntax for the OneLake File API or PySpark dataframe operations. Open the Copilot pane and type: "Generate PySpark code to read the FactSales Delta table, filter for the current calendar year, and group by Region." The Copilot agent generates the precise, optimized snippet, formats the OneLake path correctly, and includes standard error handling. Select Insert into Notebook to instantly drop the code block into the active cell.
For comprehensive guidance on programmatic environment management, refer to the official documentation: (https://learn.microsoft.com/en-us/fabric/data-engineering/how-to-use-notebook).
Scenario 3: Data Orchestration with Pipelines
You saw Jessica contrast Pipelines against Dataflow Gen2, framing Pipelines as the heavy-duty equivalent of Azure Data Factory. Today, the debate over orchestration tools is largely settled by adopting a strictly hybrid architectural approach.
Microsoft has transitioned the core capabilities of Dataflow Gen2 from preview into General Availability. This fundamentally changed the performance matrix. Dataflow Gen2 now operates exclusively on the Modern Evaluator engine, which was entirely rebuilt from the ground up on the.NET 8 framework. This drastic architectural shift severely reduces mysterious failure rates and massively improves execution speeds across more than 80 supported connectors.
Furthermore, Dataflow Gen2 introduces two critical performance toggles: Fast Copy and Partitioned Compute. Fast Copy is designed to accelerate bulk data ingestion from external sources by bypassing standard transformation logic. Partitioned Compute, conversely, is utilized to scale deep transformations across heavily fragmented, multi-file datasets.
Despite these upgrades, Fabric Pipelines remain the undisputed choice for enterprise orchestration, control flow logic, and managing complex item dependencies. The March 2026 update introduces native Change Data Capture (CDC) functionality directly within Pipeline Copy Jobs. This powerful feature enables the automated, efficient replication of inserted, updated, and deleted source records without requiring developers to manage complex high-watermark tables manually.
The industry best practice in 2026 dictates a hybrid pipeline. Teams use Dataflow Gen2 with Fast Copy enabled for the initial raw ingestion layer. They then utilize Pipelines to orchestrate the execution of those Dataflows alongside Spark Notebooks and warehouse stored procedures.
Step-by-Step March 2026 Build Instructions:
- Navigate to the workspace and locate the Task Flow visual at the top of the item list.
- Open the Add task menu and select the Get data operational task.
- Click the newly created task card, select Create new item, and choose Dataflow Gen2.
- In the Dataflow Power Query editor, select Get Data. Connect to the external source system using the enhanced connector library.
- If you are performing a direct table copy without complex data cleansing, ensure the Fast Copy toggle is explicitly enabled in the optimization settings. This bypasses the standard evaluation engine to drastically reduce compute costs.
- Define the final data destination as the managed area of your Fabric Lakehouse. Publish the Dataflow Gen2 item.
- Return to the main Task Flow canvas. Add a new task named Prepare data.
- Select this task card, choose Create new item, and select Data pipeline.
- In the Pipeline authoring canvas, drag a Dataflow activity from the top activity ribbon onto the blank grid.
- In the specific activity settings pane, link it to the previously published Dataflow Gen2 item.
- Drag subsequent activities onto the canvas, such as a Notebook activity for data transformation.
- Connect the activities with green "On Success" dependency lines to strictly dictate the order of execution.
- Configure automated unattended execution by selecting the Schedule icon in the top ribbon. Define the execution cadence (e.g., daily at 02:00 UTC).
Data pipelines in 2026 now support highly granular column-level lineage visibility natively. Using the Fabric Lineage Extractor tool, workspace administrators can trace exact data transformations backward across complex pipelines.This makes auditing workflows and debugging compliance failures vastly easier than in previous iterations.
Data Movement Strategy: Dataflow Gen2 vs. Pipelines

Best practice dictates a hybrid approach: utilize Dataflow Gen2 for high-throughput ingestion and data cleansing, while leveraging Pipelines to orchestrate the execution sequence and manage logical dependencies.
Data sources: Microsoft Learn (Transformation Guide), Medium, Microsoft Learn (Transform Data), Microsoft Learn (What's New)
Quick Win: Proactive Anomaly Detection Alerts Do not wait for business end-users to report pipeline data failures. In 2026, you should integrate Data Activator directly into your pipeline workflow. Set up conditional triggers based strictly on batch data volume thresholds. If a nightly pipeline load drops below a historical row-count average, Activator immediately triggers a high-priority alert via Microsoft Teams. This ensures data engineering visibility long before the business impact is realized.
For a complete architectural guide on orchestration, visit the official Microsoft documentation: (https://learn.microsoft.com/en-us/fabric/data-factory/transform-data).
Scenario 4: Building Semantic Models and Direct Lake Mode
You saw Jessica build a semantic model, likely relying heavily on the default auto-generated artifact created by the system. Today, default semantic models have been fully deprecated and disconnected from their parent items.
This major design change actively prevents workspace clutter and forces BI developers to intentionally design Independent Semantic Models. Direct Lake mode remains the pinnacle of performance in Fabric. Direct Lake seamlessly loads Parquet-formatted files directly into active memory from OneLake. This completely bypasses the traditional SQL compute layer, offering unparalleled rendering speeds without duplicating data.
In 2026, the Direct Lake architecture has evolved significantly. The most impactful update is the public preview of Composite Semantic Models mixing Direct Lake and Import tables. Previously, mixing high-speed Direct Lake tables with non-Fabric data sources was heavily restricted. Today, developers can seamlessly blend Direct Lake tables with standard Import tables pulling from hundreds of external Power Query connectors.
It is vital to properly understand the "Framing" concept in Direct Lake operations. Unlike traditional Import mode, which physicalizes a complete, massive cached copy of the data, a Direct Lake refresh is an extremely lightweight metadata operation. Framing simply analyzes the Delta log to update its internal references to the newest Parquet files in OneLake. This process typically completes in seconds without consuming significant capacity unit (CU) resources.
Handling relationship cardinality correctly is highly critical for VertiPaq engine performance. The current web modeling experience still does not automatically validate cardinality by actively querying the backend data. Developers must manually ensure exact data type matching and guarantee uniqueness on the "one-side" of all dimensional relationships.
Step-by-Step March 2026 Build Instructions:
- Navigate to the Fabric workspace. Open the Lakehouse item you populated in previous steps.
- Switch the context menu dropdown at the top right from the default Lakehouse view to the SQL analytics endpoint.
- In the top ribbon, explicitly select the New semantic model button.
- Provide a clear, business-friendly name and select the target workspace for deployment.
- A dialog box appears displaying all available Lakehouse objects. Select the necessary Delta tables to import.
- Warning: Do not select SQL Views. Views added to any Direct Lake model always force an immediate fallback to the slower DirectQuery mode, ruining performance. Select Confirm.
- The web modeling designer canvas opens. To define cardinality, locate the Home ribbon and select Manage relationships.
- Select + New relationship. In the "From table" dropdown, select your dimension table.
- In the "To table" dropdown, select your central fact table.
- In the Cardinality dropdown, you must explicitly select One to many (1:*).
- Set the Cross-filter direction to Single. Ensure the Assume referential integrity box is checked. This optimizes the internal DAX query generation engine. Select Save.
- To extend this structure into a Composite Model, select Get data from the web ribbon.
- Connect to an external source, such as a localized Excel mapping file on SharePoint.
- The platform ingests this external table via standard Import mode, seamlessly placing it alongside the Direct Lake tables. Regular, performant relationships can now be established between the two differing storage modes.
For highly advanced modeling tasks, such as adding complex DAX calculation groups or managing Row-Level Security (RLS) rules, you must leverage the live editing capability. Select the Editing dropdown in the top right corner and choose Edit in Desktop. This launches your local installation of Power BI Desktop, connected directly to the live, in-memory Fabric model.
Quick Win: Programmatic Semantic Model Migration Migrating legacy Power BI Import models to the new Direct Lake architecture no longer requires tedious manual rebuilding. Utilize the open-source Semantic Link Labs library natively within a Fabric Notebook. Install the Python library, define the source Import model ID, and execute the automated migration script. The library dynamically generates the required Delta tables in the Lakehouse, migrates all calculation groups, and seamlessly ports over all DAX measures automatically.
For further strict specifications on Direct Lake design patterns, refer to the documentation: (https://learn.microsoft.com/en-us/fabric/fundamentals/direct-lake-overview).
Scenario 5: Power BI Integration and Report Creation
The final component of Jessica's session demonstrated surfacing Lakehouse data into interactive Power BI reports. Today, the reporting workflow is deeply augmented by agentic AI and streamlined interface updates.
Report creation is now seamlessly integrated directly within the Fabric portal, minimizing jarring context switching to external desktop tools. Furthermore, the January 2026 update introduced AI Auto-Summary specifically for semantic models operating within the OneLake Catalog.
The Copilot engine automatically scans the deep metadata and relational structure of a published semantic model. It then generates a plain-text, easily digestible summary of the model's primary purpose, key metrics, and intended audience. This drastically accelerates data discovery and onboarding for new report builders operating within large enterprise tenants.
Step-by-Step March 2026 Build Instructions:
- Ensure the Independent Semantic Model you created in Scenario 4 is successfully published and accessible in the central production workspace.
- Navigate to the workspace and click directly on the Semantic Model item.
- The updated 2026 Item Details page launches. This page now displays comprehensive schema visualizations, data lineage tracking, and granular refresh history logs in a single unified view.
- In the top command ribbon of the Item Details page, select Create a report.
- The system presents two primary options. Choose Auto-create to allow the AI to generate an initial dashboard layout based on the underlying schema.
- Alternatively, choose Start from scratch to open a completely blank report canvas.
- If starting from scratch, the web-based report builder interface launches, mirroring the familiar Power BI Desktop experience.
- Expand the available tables in the right-hand Data pane. Drag and drop categorical and numerical fields directly onto the canvas to construct your visuals.
- Direct Lake models respond instantaneously to rapid filter context changes. The DAX queries are processed directly by the VertiPaq engine against the in-memory Parquet data, eliminating loading spinners.
- When the visual layout is finalized, select File > Save to commit the report artifact directly into the Fabric workspace repository.
To distribute the finalized report securely to business users, organizations must utilize Fabric Workspace Apps. The 2026 OneLake Catalog natively surfaces these Workspace Apps directly in the UI. This provides end-users with a centralized, governed storefront to discover and consume authorized reporting content, completely bypassing the messy underlying workspace infrastructure.
Quick Win: Instant Copilot Exploration When exploring entirely unfamiliar datasets, do not waste valuable engineering time manually building diagnostic visuals. Open the semantic model in the web view and activate Copilot for exploration.Ask natural-language analytical questions such as, "Show me the top five regions by sales volume over the last four trailing quarters." Copilot instantly translates the intent, queries the semantic model, generates a temporary visualization, and provides text-based analytical summaries without requiring you to write a single line of DAX.
For comprehensive instructions on establishing continuous integration and reporting workflows, visit the documentation: (https://learn.microsoft.com/en-us/fabric/cicd/deployment-pipelines/intro-to-deployment-pipelines).
Licensing Quick Reference
You saw Jessica broadly mention Fabric capacities during the mid-2024 session. Today, understanding the precise F-SKU licensing model defines your entire architectural capability. Administration is now entirely integrated directly into the overarching Microsoft Fabric tenant interface.
The primary distinction in Fabric licensing lies between individual user licenses (Free, Pro, Premium Per User) and organizational compute capacity licenses (F-SKUs). A dedicated Fabric capacity is strictly required to execute heavy Fabric workloads, such as running Spark compute clusters, executing Data Pipelines, or framing Direct Lake models.
The following table outlines the strict minimum licensing requirements for common organizational deployment scenarios in 2026.
| Architectural Scenario | Capacity Requirement | End-User License Requirement | Creator License Requirement |
|---|---|---|---|
| Enterprise Deployment (High Scale) | F64 (or larger) | Free License | Power BI Pro or PPU |
| Small/Medium Business Deployment | F2 to F32 | Power BI Pro or PPU | Power BI Pro or PPU |
| Isolated Per-User Workloads | None (Shared Capacity) | PPU | PPU |
| Traditional BI Only (No Fabric Compute) | None | Power BI Pro | Power BI Pro |
Note on Capacity Thresholds: The F64 SKU represents the most critical administrative boundary in the platform. Capacities sized at F64 or above exclusively grant unlimited "free" viewers the ability to consume published Power BI content without a named license. Deployments utilizing any F-SKU below F64 strictly require every single consuming user to hold a paid Power BI Pro or PPU license to view reports.
Briefing published by Collab365 Spaces. Cite as "2026 Update: Microsoft Fabric Foundations Companion Guide", Collab365 Spaces. 47 sources referenced.